我有一个单节点的k8s集群,部署在我自己电脑的vmware虚拟机上,平时就是用的时候开机,不用的时候关机。都用了大半年了,一直好好的,突然最近集群挂掉了,重启机器也没得用,搞得我我心痛,里面好多应用数据。
一、k8s部署方式
参考:allinone部署
二、现状
-
kubectl无法执行,没有输出
-
docker ps看到没有容器在运行
[root@k8s ~]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 6fe1ee41bff1 easzlab/kubeasz:3.1.0 "sleep 36000" 2 months ago Up 27 hours kubeasz
三、排查
首先看kubelet日志
Jul 30 22:38:44 k8s kubelet[784001]: E0730 22:38:44.170038 784001 kubelet_node_status.go:93] "Unable to register node with API server" err="Post \"https://127.0.0.1:6443/api/v1/nodes\": EOF" node="192.168.66.143"
都是连接不到6443的错误,但是端口可以看到是监听的
[root@k8s ~]# ss -ltn | grep :6443
LISTEN 13 4096 192.168.66.143:6443 0.0.0.0:*
LISTEN 0 511 127.0.0.1:6443 0.0.0.0:*
因为6443端口是api-server这边的,所以需要看下api-server的日志
[root@k8s ~]# journalctl -u kube-apiserver.service
Jul 30 22:37:58 k8s kube-apiserver[787977]: I0730 22:37:58.660582 787977 endpoint.go:68] ccResolverWrapper: sending new addresses to cc: [{https://192.168.66.143:2379 <nil> 0 <nil>}]
Jul 30 22:37:58 k8s kube-apiserver[787977]: W0730 22:37:58.660983 787977 clientconn.go:1223] grpc: addrConn.createTransport failed to connect to {https://192.168.66.143:2379 <nil> 0 <nil>}. Err :connection error: desc = "transport: Error while dialing dial tcp 192.168.66.143:2379: connect: connection refused". Reconnecting...
Jul 30 22:37:59 k8s kube-apiserver[787977]: I0730 22:37:59.656938 787977 client.go:360] parsed scheme: "endpoint"
Jul 30 22:37:59 k8s kube-apiserver[787977]: I0730 22:37:59.657012 787977 endpoint.go:68] ccResolverWrapper: sending new addresses to cc: [{https://192.168.66.143:2379 <nil> 0 <nil>}]
Jul 30 22:37:59 k8s kube-apiserver[787977]: W0730 22:37:59.657589 787977 clientconn.go:1223] grpc: addrConn.createTransport failed to connect to {https://192.168.66.143:2379 <nil> 0 <nil>}. Err :connection error: desc = "transport: Error while dialing dial tcp 192.168.66.143:2379: connect: connection refused". Reconnecting...
Jul 30 22:37:59 k8s kube-apiserver[787977]: W0730 22:37:59.661557 787977 clientconn.go:1223] grpc: addrConn.createTransport failed to connect to {https://192.168.66.143:2379 <nil> 0 <nil>}. Err :connection error: desc = "transport: Error while dialing dial tcp 192.168.66.143:2379: connect: connection refused". Reconnecting...
Jul 30 22:38:00 k8s kube-apiserver[787977]: W0730 22:38:00.659230 787977 clientconn.go:1223] grpc: addrConn.createTransport failed to connect to {https://192.168.66.143:2379 <nil> 0 <nil>}. Err :connection error: desc = "transport: Error while dialing dial tcp 192.168.66.143:2379: connect: connection refused". Reconnecting...
Jul 30 22:38:01 k8s kube-apiserver[787977]: W0730 22:38:01.042207 787977 clientconn.go:1223] grpc: addrConn.createTransport failed to connect to {https://192.168.66.143:2379 <nil> 0 <nil>}. Err :connection error: desc = "transport: Error while dialing dial tcp 192.168.66.143:2379: connect: connection refused". Reconnecting...
Jul 30 22:38:02 k8s kube-apiserver[787977]: W0730 22:38:02.152989 787977 clientconn.go:1223] grpc: addrConn.createTransport failed to connect to {https://192.168.66.143:2379 <nil> 0 <nil>}. Err :connection error: desc = "transport: Error while dialing dial tcp 192.168.66.143:2379: connect: connection refused". Reconnecting...
可以看到是连接不到etcd,我们再看etcd的日志
recovering backend from snapshot error: failed to find database snapshot file (snap: snapshot file doesn't exist)
Failed to start Etcd Server.
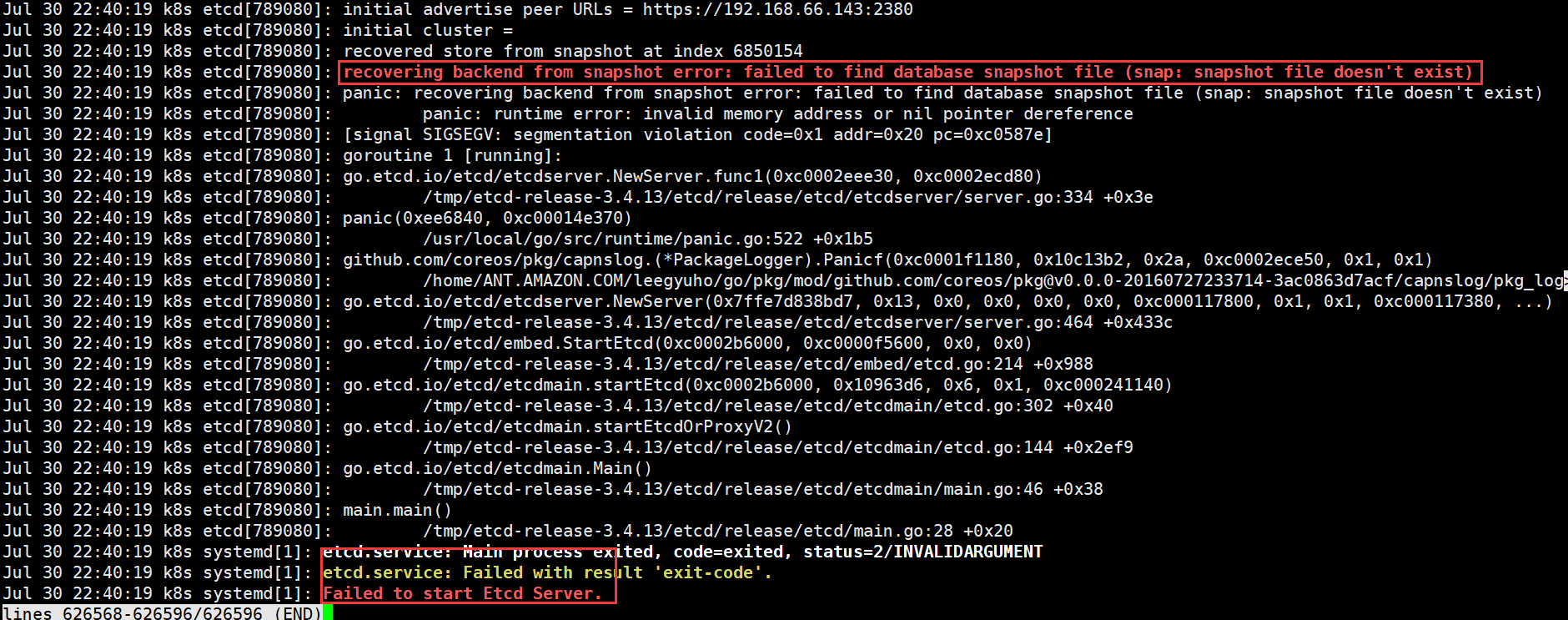
etcd挂掉可就完蛋了,顺着这个报错去社区里面搜索,找到了下面这些:
-
vmware死机导致etcd挂掉,最终含泪删除etcd数据:https://blog.csdn.net/Urms_handsomeyu/article/details/112018338
-
Panic of snapshot not find after power failure does it have any solution!
这些问题的共同点都是:意外断电,无法恢复。当然有个小伙伴说他恢复了,因为我是单节点的,无法验证。
四、经验总结
etcd定时备份!etcd定时备份!etcd定时备份!重要事情说三遍!!!我也终于体会到了CKA考试里面etcd备份还原的良苦用心。
提前在测试环境发现问题是好事情,我们要吸取教训!
五、关于etcd备份
参考:https://etcd.io/docs/v3.5/op-guide/recovery/#snapshotting-the-keyspace
参考:https://github.com/easzlab/kubeasz/blob/master/docs/op/op-etcd.md
参考:https://github.com/easzlab/kubeasz/blob/master/docs/op/cluster_restore.md
1、手动备份
~]# ETCDCTL_API=3 etcdctl --cacert="" --cert="" --key="" snapshot save snapshot.db
# 查看备份
ETCDCTL_API=3 etcdctl --write-out=table snapshot status snapshot.db
2、使用kubeasz官方的备份还原
https://github.com/easzlab/kubeasz/blob/master/docs/op/cluster_restore.md
#备份
3、编写cronjob定时备份
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: backup-etcd
spec:
schedule: "0 */3 * * *" # 每3小时执行一次
concurrencyPolicy: Forbid
successfulJobsHistoryLimit: 1
failedJobsHistoryLimit: 1
jobTemplate:
spec:
activeDeadlineSeconds: 120
backoffLimit: 3
template:
spec:
containers:
- name: etcd-backup
image: etcd:v3.3.13 # 就是quay.io/coreos/etcd 建议找一台可以访问外网的机器下载后上传到私有仓库里
imagePullPolicy: IfNotPresent
env:
- name: ETCDCTL_API
value: "3"
- name: ETCD_ADDR
valueFrom:
fieldRef:
fieldPath: status.hostIP
command:
- /bin/sh
- /etcd-backup.sh
resources:
limits:
cpu: "1"
memory: 1Gi
volumeMounts:
- name: etcd-ssl
mountPath: /var/lib/etcd/ssl
readOnly: true
- name: etcd-backup
mountPath: /var/lib/etcd/snapshot
- name: etcd-backup-script
mountPath: /etcd-backup.sh
subPath: etcd-backup.sh
- name: localtime
mountPath: /etc/localtime
volumes:
- name: etcd-backup-script
configMap:
defaultMode: 0755
name: etcd-backup-script
- name: etcd-ssl
hostPath:
path: /var/lib/etcd/ssl
- name: etcd-backup
hostPath:
path: /var/lib/etcd/snapshot
type: DirectoryOrCreate
- name: localtime
hostPath:
path: /etc/localtime
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: loadbalance.caicloud.io/kube-system.apiserver
operator: In
values:
- "true"
tolerations:
- effect: NoSchedule
operator: Exists
- key: CriticalAddonsOnly
operator: Exists
- effect: NoExecute
operator: Exists
restartPolicy: Never
---
apiVersion: v1
kind: ConfigMap
metadata:
name: etcd-backup-script
data:
etcd-backup.sh: |-
#!/bin/bash
SNAPSHOT_PATH="/var/lib/etcd/snapshot"
# get ETCD cluster endpoints information
ENDPOINTS="`etcdctl --endpoints=https://${POD_IP}:2379 --cacert=/var/lib/etcd/ssl/ca.crt --cert=/var/lib/etcd/ssl/etcd.crt --key=/var/lib/etcd/ssl/etcd.key member list | awk -F ", " '{printf $5","}' | sed 's/,$//'`"
if [ ! ${ENDPOINTS} ];then
echo "`date +'%Y-%m-%d %T'` || [Error] Failed to get ETCD cluster information "
exit 255
else
echo "`date +'%Y-%m-%d %T'` || [INFO] Get ETCD cluster information success"
fi
# get ETCD leader information for snapshot
ETCD_LEADER_ADDR="`etcdctl --endpoints=${ENDPOINTS} --cacert=/var/lib/etcd/ssl/ca.crt --cert=/var/lib/etcd/ssl/etcd.crt --key=/var/lib/etcd/ssl/etcd.key endpoint status | grep "true" | awk '{print $1}' | sed 's/,$//'`"
if [ ! ${ETCD_LEADER_ADDR} ];then
echo "`date +'%Y-%m-%d %T'` || [Error] Failed to get ETCD leader address"
exit 255
else
echo "`date +'%Y-%m-%d %T'` || [INFO] Get ETCD leader endpoint success"
fi
# snapshot ETCD leader node
etcdctl --endpoints=${ETCD_LEADER_ADDR} --cacert=/var/lib/etcd/ssl/ca.crt --cert=/var/lib/etcd/ssl/etcd.crt --key=/var/lib/etcd/ssl/etcd.key snapshot save ${SNAPSHOT_PATH}/etcd-backup-`date +'%Y-%m-%d_%T'`.db >> /dev/null 2>&1
if [ $? != 0 ];then
echo "`date +'%Y-%m-%d %T'` || [Error] Backup ETCD failed, currently ETCD Leader: ${ETCD_LEADER_ADDR}"
exit 255
else
echo "`date +'%Y-%m-%d %T'` || [INFO] Backup ETCD success, currently ETCD Leader: ${ETCD_LEADER_ADDR}"
fi
# snapshot is retained for 72h
find ${SNAPSHOT_PATH} -type f -mtime +2 -name "*.db" -exec rm -f {} \;