一、问题产生背景
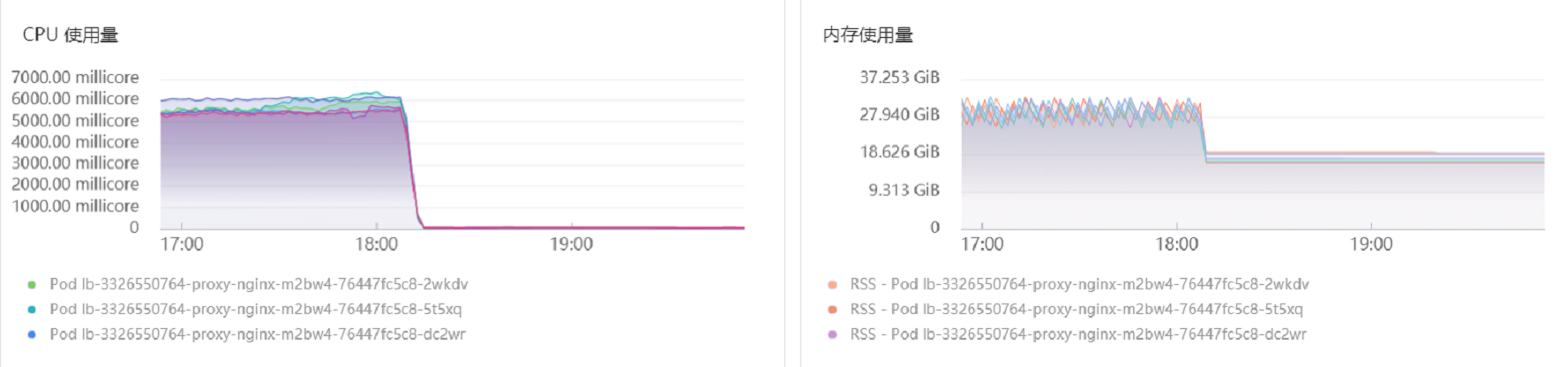
我们在k8s里面搭了一套elk集群,使用nginx ingres将kibana,elasticsearch,logstash服务等代理出来,然后发现ingress内存和CPU使用异常高,可以把物理机的内存吃满,然后oom,又继续增长。见下图:
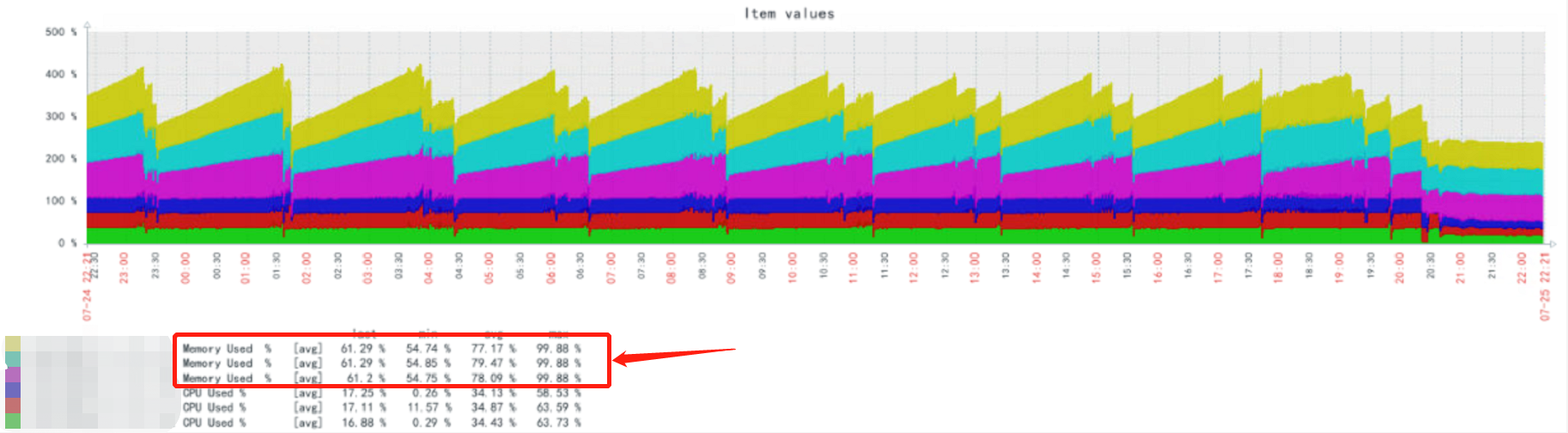
临时解决办法,只能先将CPU内存限制在32C32G,但是依旧吃满32G内存,所以需要排查
ingress容器里面dmesg显示OOM的信息,cgroup发现内存不足后,会选择一些进程kill掉


二、查看容器里面进程内存分配情况
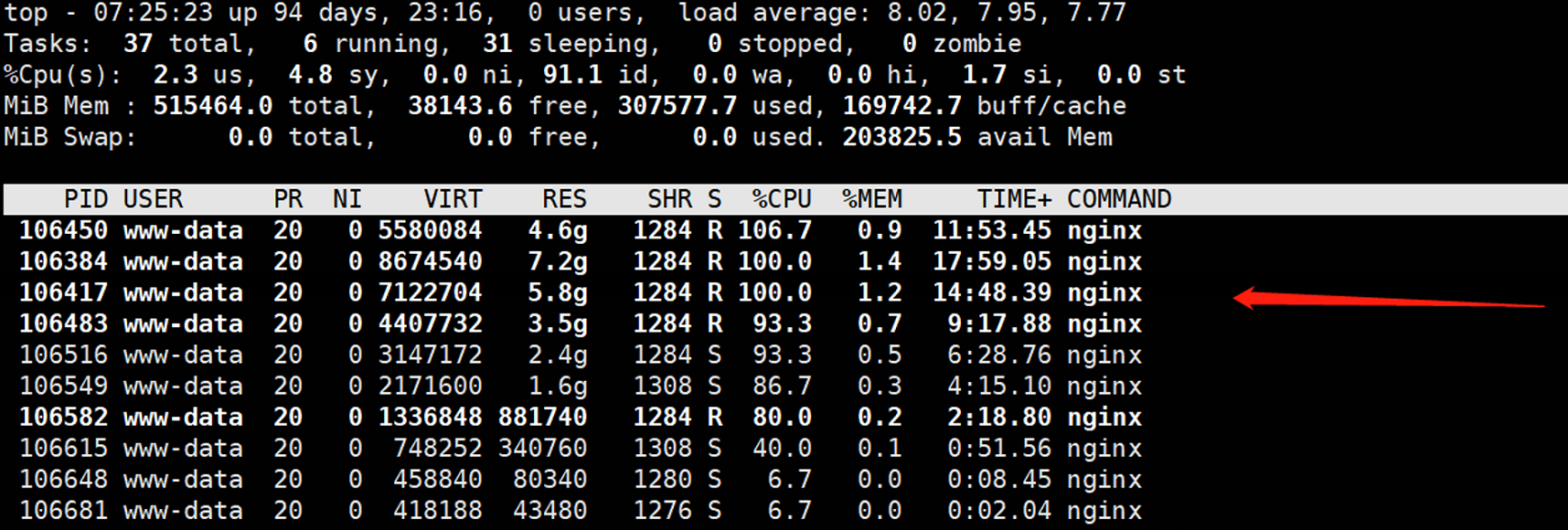
三、pmap命令查看nginx进程内存分配情况
pmap命令,gcore命令等都需要 特权模式下才可以正常执行。以特权模式,root身份进入ingress容器
(以下操作全部在容器内部进行)
~]$ docker exec -u root --privileged -it 8e3 bash
# 分析107751这个进程的内存使用情况
~]$ pmap -x 107751 | less -N
可以看到有两块anon的东西占用了总共5个多g的内存
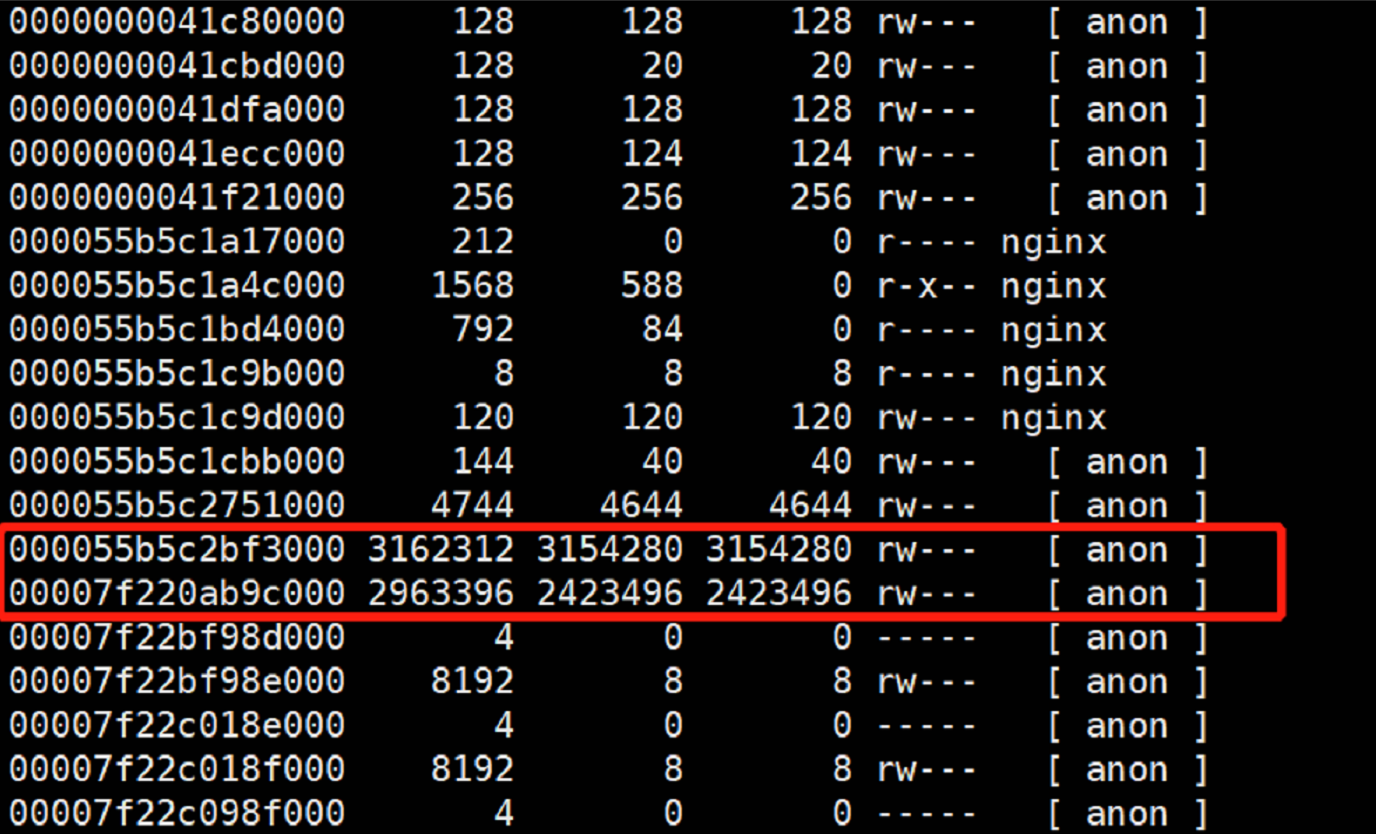
四、定位内存泄露的地址范围
~]$ cat /proc/107751/smaps
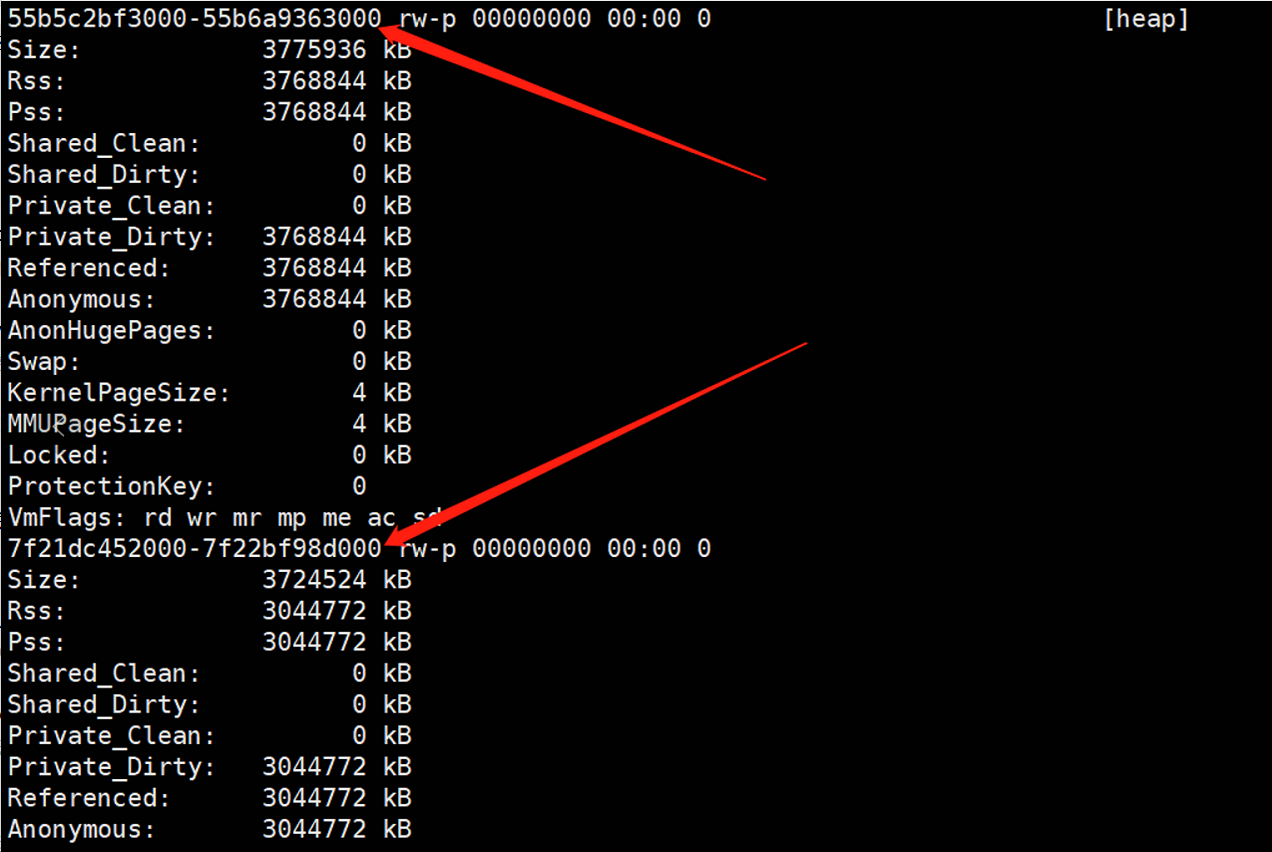
五、gcore转储内存映像及内存上下文
~]$ gcore 107751
这样就得到了一个core.107751的文件
注意: 一定要在容器里面执行,如果在容器外面执行会报下面这个错误:
~]$ gcore 834061
/usr/sbin/nginx: No such file or directory.
warning: Memory read failed for corefile section, 8192 bytes at 0xc1c9b000.
warning: Memory read failed for corefile section, 122880 bytes at 0xc1c9d000.
warning: Memory read failed for corefile section, 147456 bytes at 0xc1cbb000.
warning: Memory read failed for corefile section, 1048576 bytes at 0xc2751000.
六、使用gdb加载内存信息
~]$ gdb -core core.107751
dump binary 导出泄露内存的内容 内存地址就是第四步拿到的那个内存地址

七、分析二进制文件worker-pid.bin
可以直接使用hexdump命令来查看二进制文件
# -C表示输出格式为二进制+ASCII码的形式展示;-n 1000000表示只读取文件前1000000个字节
~]$ hexdump -C -n 1000000 worker-pid.bin &> worker.txt
然后就可以使用vim打开worker.txt文件了。
可以看到都是xxx:5044这些信息,这个是后端logstash的地址信息,因为是4层轮训的,所以显示的ip都不同
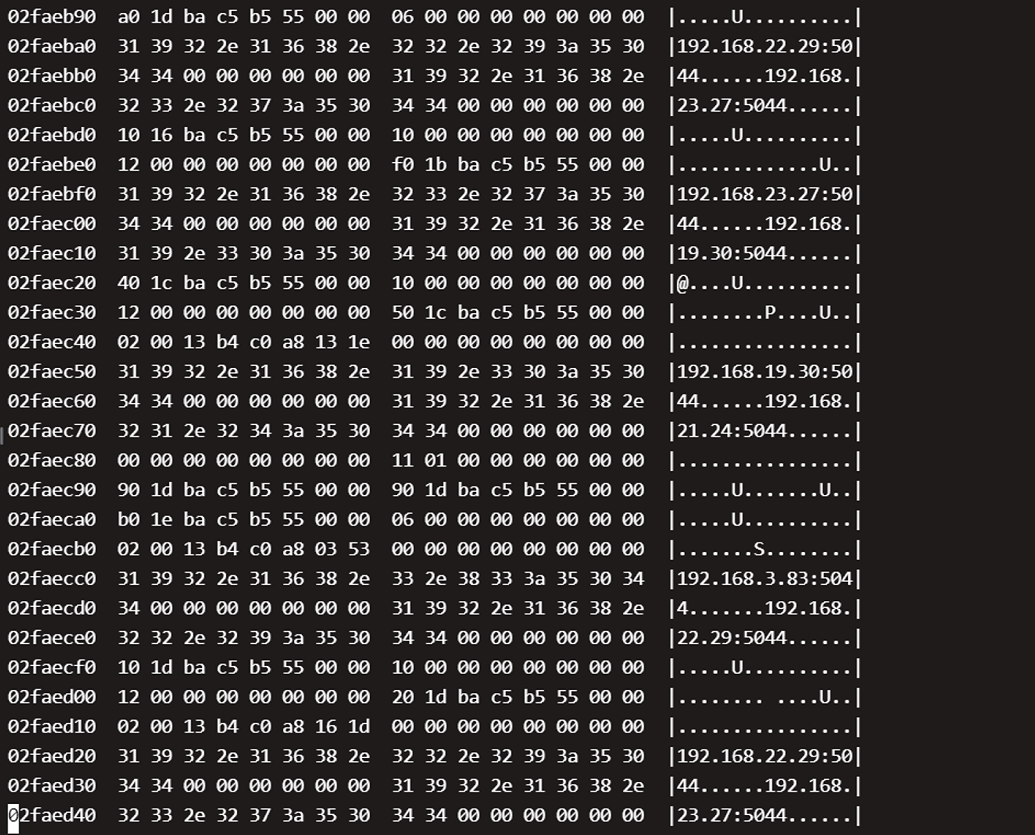
并且在ingress日志里面,看到了ingress连接后端logstash的报错信息
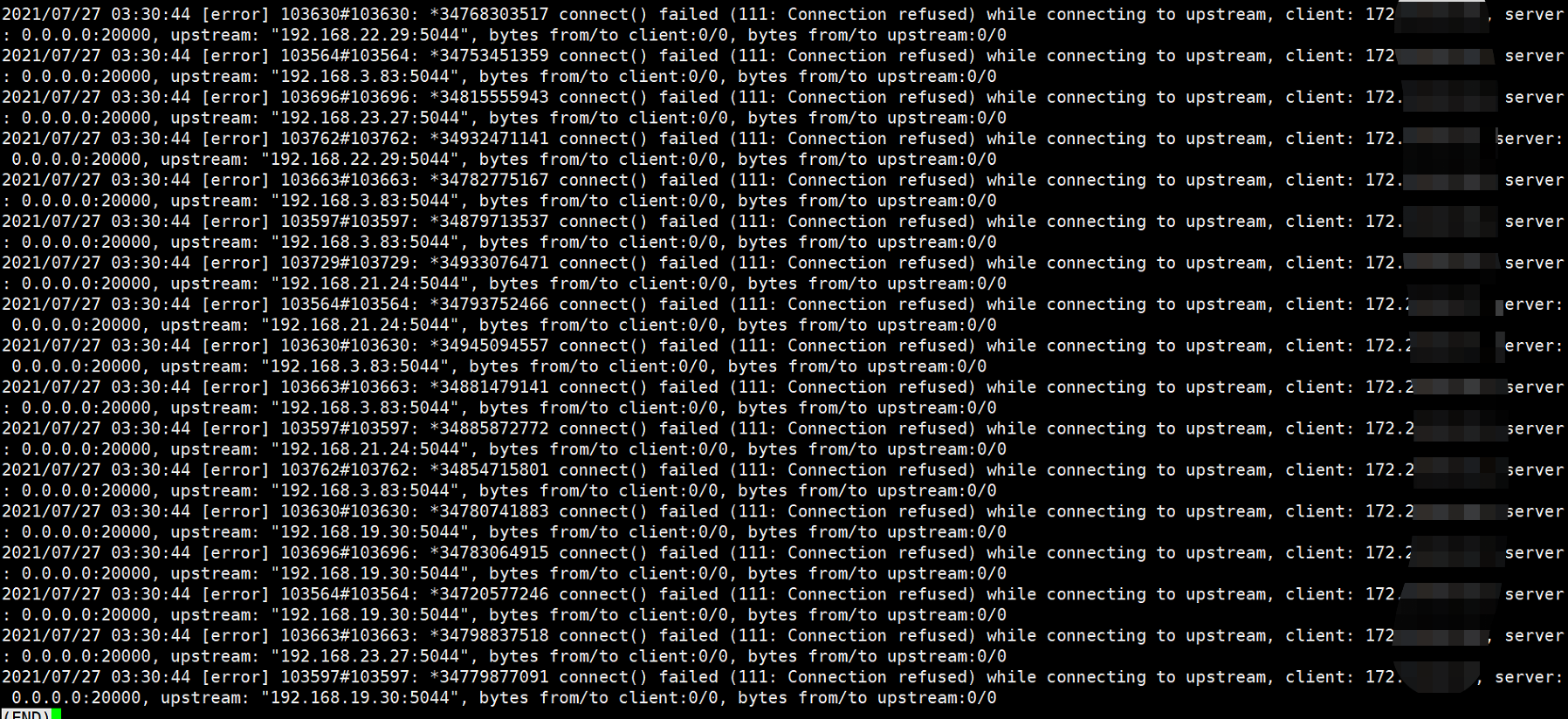
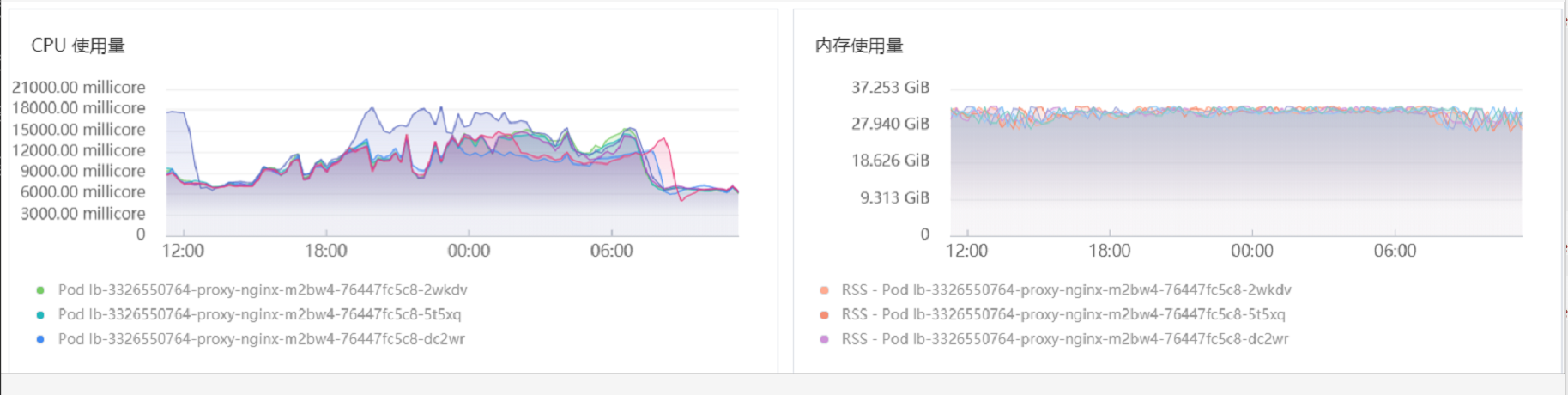
经过确认,后端logstash确实不通,导致大量的请求堆积在内存里面。 和ELK伙伴确认后,及时修复后端logstash问题,然后再观察ingress内存,终于恢复正常: