EFK教程 - EFK快速入门指南
参考:https://mp.weixin.qq.com/s/Kzqllh5VQedss2u-DSrDhQ
通过部署elasticsearch(三节点)+filebeat+kibana快速入门EFK,并搭建起可用的demo环境测试效果
用途:
▷ 通过filebeat实时收集nginx访问日志、传输至elasticsearch集群
▷ filebeat将收集的日志传输至elasticsearch集群
▷ 通过kibana展示日志
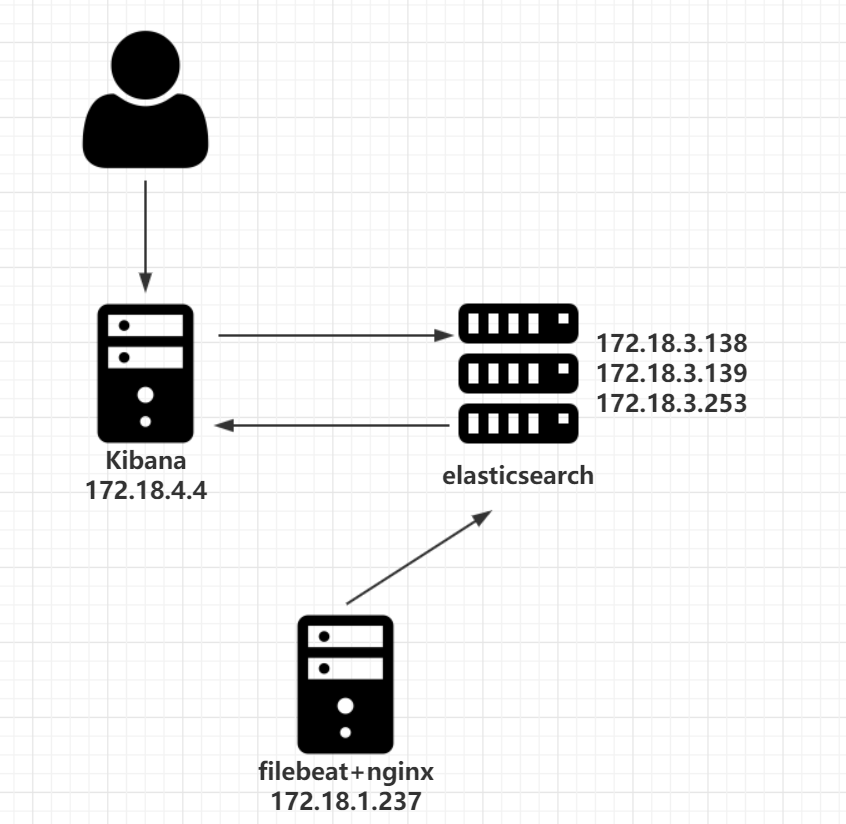
实验架构:
▷ 服务器配置:
| 名称 | IP | CPU | 内存 |
|---|---|---|---|
| filebeat | 172.18.1.237 | 2 | 2G |
| kibana | 172.18.4.4 | 2 | 2G |
| elasticsearch-1 | 172.18.3.138 | 4 | 4G |
| elasticsearch-2 | 172.18.3.139 | 4 | 4G |
| elasticsearch-3 | 172.18.3.253 | 4 | 4G |
▷ 架构图
一、安装elasticsearch
三个机器都执行脚本
[root@es-1 ~]# cat install_elasticsearch.sh
mkdir -p /opt/software && cd /opt/software
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.3.2-linux-x86_64.tar.gz
tar -zxvf elasticsearch-7.3.2-linux-x86_64.tar.gz
mv elasticsearch-7.3.2 /opt/elasticsearch
useradd elasticsearch -d /opt/elasticsearch -s /sbin/nologin
mkdir -p /opt/logs/elasticsearch
chown elasticsearch.elasticsearch /opt/elasticsearch -R
chown elasticsearch.elasticsearch /opt/logs/elasticsearch -R
# 限制一个进程可以拥有的VMA(虚拟内存区域)的数量要超过262144,不然elasticsearch会报max virtual memory areas vm.max_map_count [65535] is too low, increase to at least [262144]
echo "vm.max_map_count = 655350" >> /etc/sysctl.conf
sysctl -p
二、安装filebeat
[root@nginx-1 ~]# cat install_filebeat.sh
mkdir -p /opt/software && cd /opt/software
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.3.2-linux-x86_64.tar.gz
mkdir -p /opt/logs/filebeat/
tar -zxvf filebeat-7.3.2-linux-x86_64.tar.gz
mv filebeat-7.3.2-linux-x86_64 /opt/filebeat
[root@nginx-1 ~]# bash install_filebeat.sh
三、安装kibana
[root@kibana ~]# cat install_kibana.sh
mkdir -p /opt/software && cd /opt/software
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.3.2-linux-x86_64.tar.gz
tar -zxvf kibana-7.3.2-linux-x86_64.tar.gz
mv kibana-7.3.2-linux-x86_64 /opt/kibana
useradd kibana -d /opt/kibana -s /sbin/nologin
chown kibana.kibana /opt/kibana -R
[root@kibana ~]# bash install_kibana.sh
四、nginx安装(用于生成日志,被filebeat收集)
[root@nginx-1 ~]# yum install nginx -y
[root@nginx-1 ~]# nginx -c /etc/nginx/nginx.conf
五、elasticsearch配置
es-1(172.18.3.138)
vim /opt/elasticsearch/config/elasticsearch.yml
#集群名字
cluster.name: 007-project
#节点名字
node.name: es-1
#日志位置
path.logs: /opt/logs/elasticsearch
#本节点访问IP
network.host: 172.18.3.138
#本结点访问端口
http.port: 9200
#节点运输端口
transport.port: 9300
#集群中其他主机的列表
discovery.seed_hosts: ["es-1", "es-2", "es-3"]
#首次启动全新的Elasticsearch集群时,在第一次选举中便对其票数进行计数的master节点的集合
cluster.initial_master_nodes: ["es-1", "es-2","es-3"]
#启用跨域资源共享
http.cors.enabled: true
http.cors.allow-origin: "*"
#只要有2台数据或主节点已加入集群,就可以恢复
gateway.recover_after_nodes: 2
es-1(172.18.3.139)
vim /opt/elasticsearch/config/elasticsearch.yml
#集群名字
cluster.name: 007-project
#节点名字
node.name: es-2
#日志位置
path.logs: /opt/logs/elasticsearch
#本节点访问IP
network.host: 172.18.3.139
#本结点访问端口
http.port: 9200
#节点运输端口
transport.port: 9300
#集群中其他主机的列表
discovery.seed_hosts: ["es-1", "es-2", "es-3"]
#首次启动全新的Elasticsearch集群时,在第一次选举中便对其票数进行计数的master节点的集合
cluster.initial_master_nodes: ["es-1", "es-2","es-3"]
#启用跨域资源共享
http.cors.enabled: true
http.cors.allow-origin: "*"
#只要有2台数据或主节点已加入集群,就可以恢复
gateway.recover_after_nodes: 2
es-1(172.18.3.253)
vim /opt/elasticsearch/config/elasticsearch.yml
#集群名字
cluster.name: 007-project
#节点名字
node.name: es-3
#日志位置
path.logs: /opt/logs/elasticsearch
#本节点访问IP
network.host: 172.18.3.253
#本结点访问端口
http.port: 9200
#节点运输端口
transport.port: 9300
#集群中其他主机的列表
discovery.seed_hosts: ["es-1", "es-2", "es-3"]
#首次启动全新的Elasticsearch集群时,在第一次选举中便对其票数进行计数的master节点的集合
cluster.initial_master_nodes: ["es-1", "es-2","es-3"]
#启用跨域资源共享
http.cors.enabled: true
http.cors.allow-origin: "*"
#只要有2台数据或主节点已加入集群,就可以恢复
gateway.recover_after_nodes: 2
六、filebeat配置
nginx(172.18.1.237)
vim /opt/filebeat/filebeat.yml
# 文件输入
filebeat.inputs:
# 文件输入类型
- type: log
# 开启加载
enabled: true
# 文件位置
paths:
- /var/log/nginx/*.log
# 自定义参数
fields:
type: nginx_access
filebeat.config.modules:
path: ${path.config}/modules.d/*.yml
reload.enabled: false
setup.template.settings:
index.number_of_shards: 1
setup.kibana:
# 输出至elasticsearch
output.elasticsearch:
# elasticsearch集群
hosts: ["http://172.18.3.138:9200",
"http://172.18.3.139:9200",
"http://172.18.3.253:9200"]
# 索引配置
indices:
- index: "nginx_access_%{+yyy.MM}"
# 当类型是nginx_access时使用此索引
when.equals:
fields.type: "nginx_access"
# 关闭自带模板
setup.template.enabled: false
# 开启日志记录
logging.to_files: true
processors:
- add_host_metadata: ~
- add_cloud_metadata: ~
# 日志等级
logging.level: info
# 日志文件
logging.files:
# 日志位置
path: /opt/logs/filebeat/
# 日志名字
name: filebeat
# 日志轮转期限,必须要2~1024
keepfiles: 7
# 日志轮转权限
permissions: 0600
七、kibana配置
kibana(172.18.4.4)
vim /opt/kibana/config/kibana.yml
# 本节点访问端口
server.port: 5601
# 本节点IP
server.host: "kibana"
# elasticsearch集群IP
elasticsearch.hosts: ["http://172.18.3.138:9200",
"http://172.18.3.139:9200",
"http://172.18.3.253:9200"]
八、启动服务
#elasticsearch启动(3台es均启动)
sudo -u elasticsearch /opt/elasticsearch/bin/elasticsearch
#filebeat启动
/opt/filebeat/filebeat -e -c /opt/filebeat/filebeat.yml -d "publish"
# kibana启动
sudo -u kibana /opt/kibana/bin/kibana -c /opt/kibana/config/kibana.yml
kibana启动会报错:
sudo -u kibana /opt/kibana/bin/kibana -c /opt/kibana/config/kibana.yml
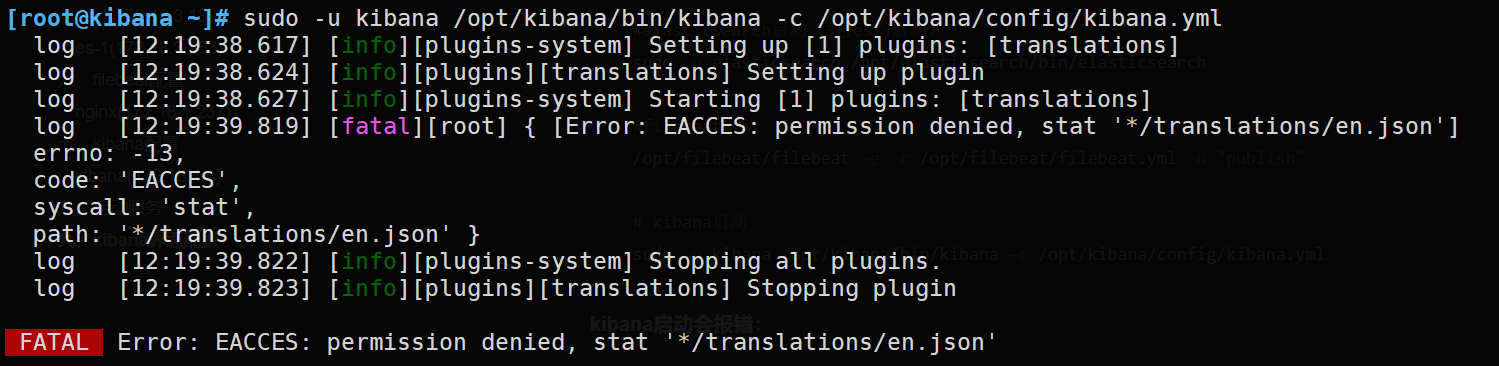
暂时解决:用root启动:/opt/kibana/bin/kibana -c /opt/kibana/config/kibana.yml --allow-root
九、kibana界面配置
1、访问到下面界面表示kibana成功了:

2、点‘try ouer sample data’
3、选no,不让kibana统计信息

4、选web log那个模版,点击添加data到kibana
5、进入视图(dashboard)
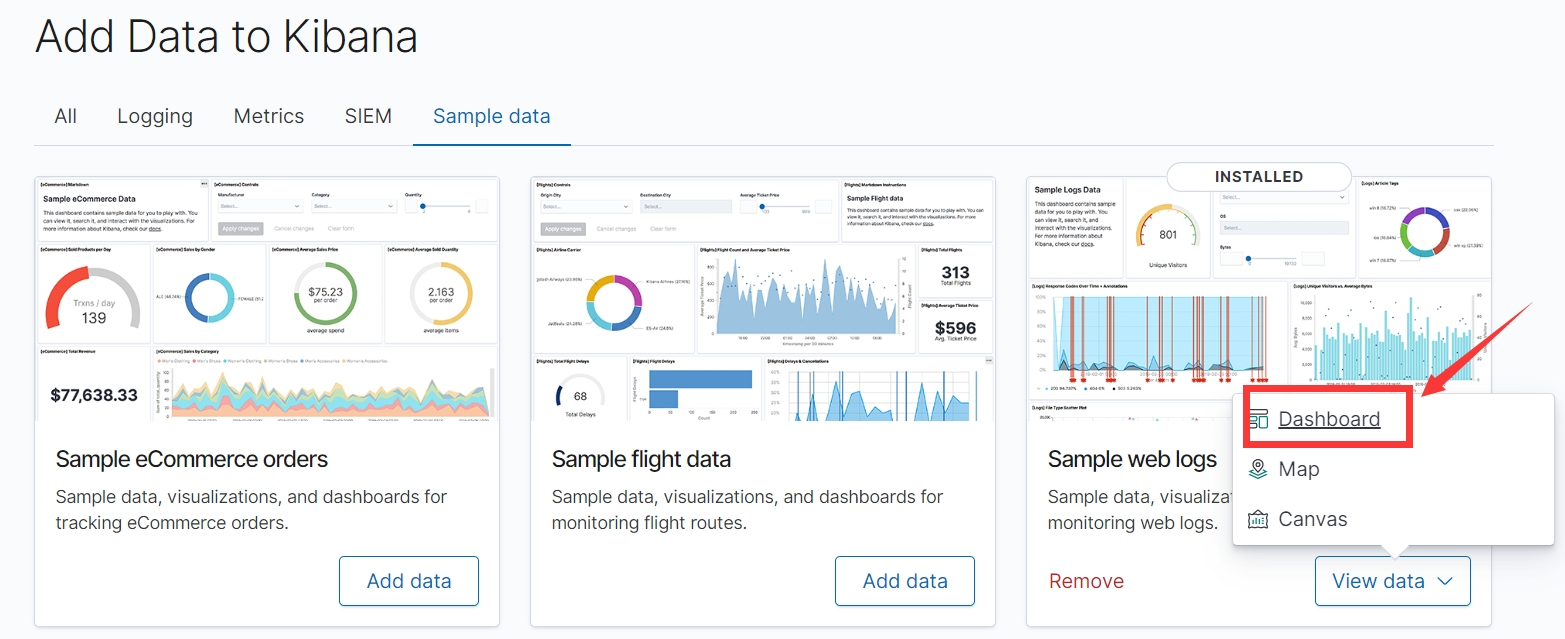
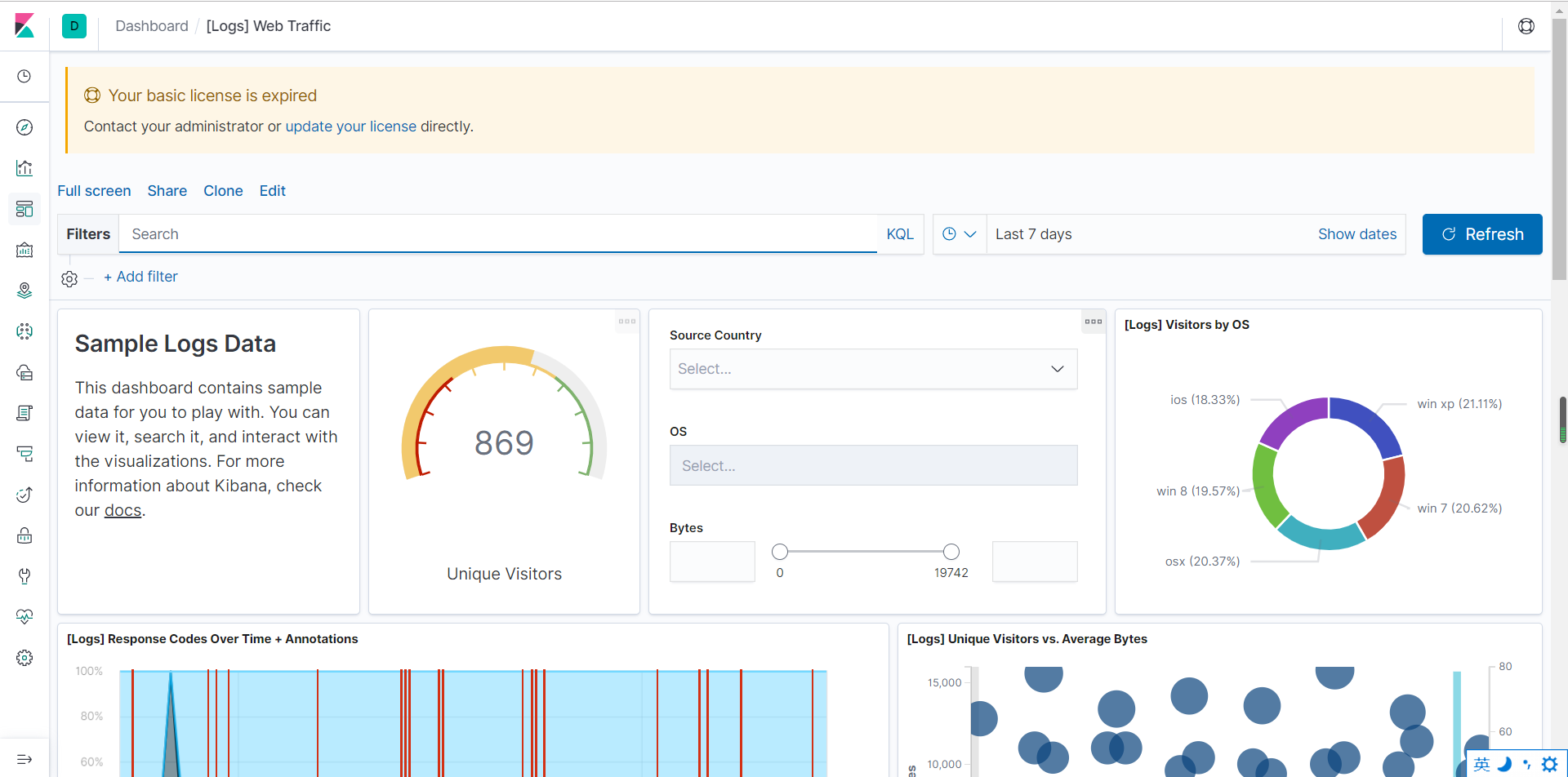
十、测试
1、访问nginx,产生日志
[root@node1 ~]# curl http://172.18.1.237/
2、在kibana上看数据
(1)创建索引模版
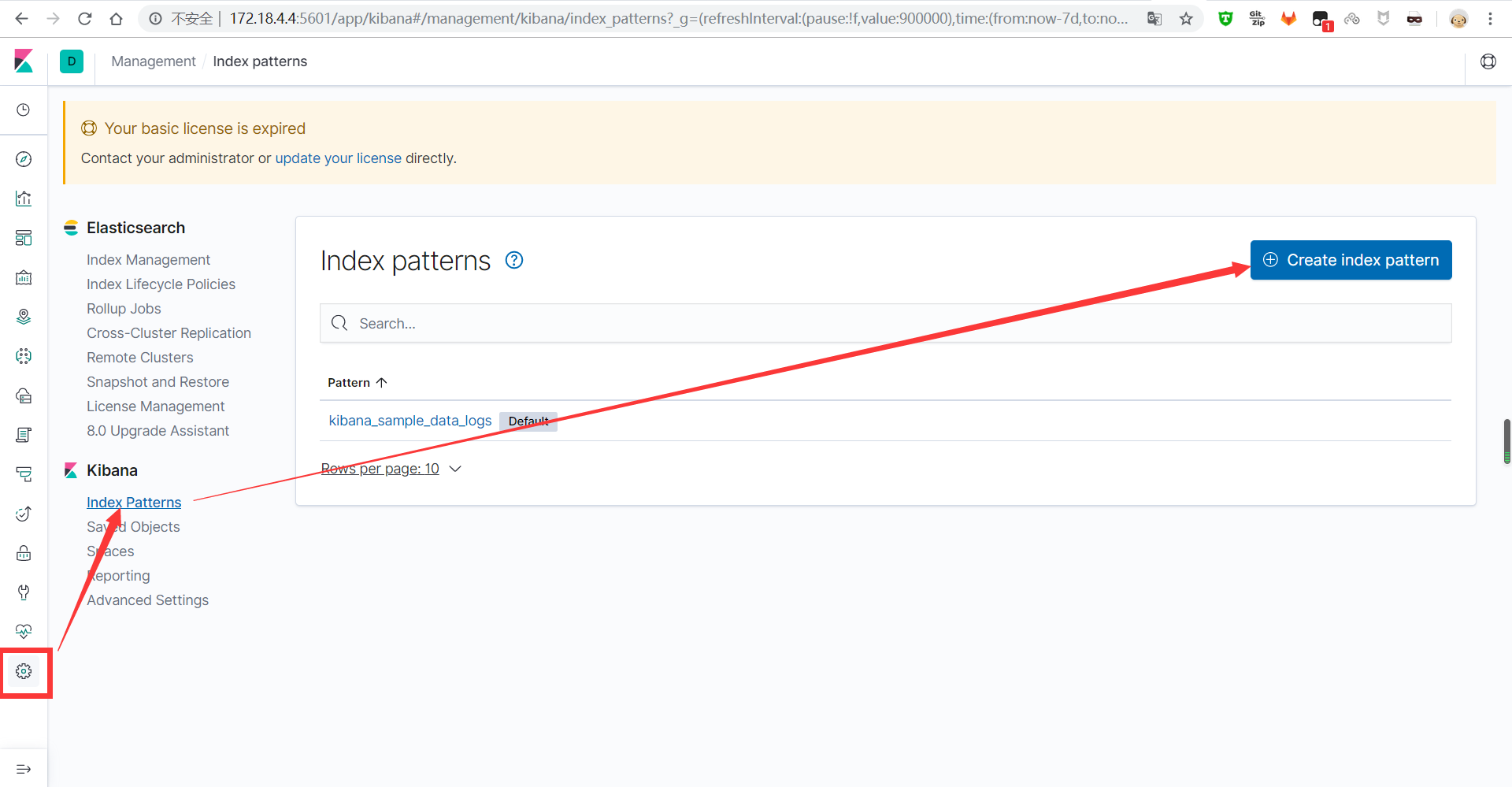
(2)输入你要创建的索引模板的名字
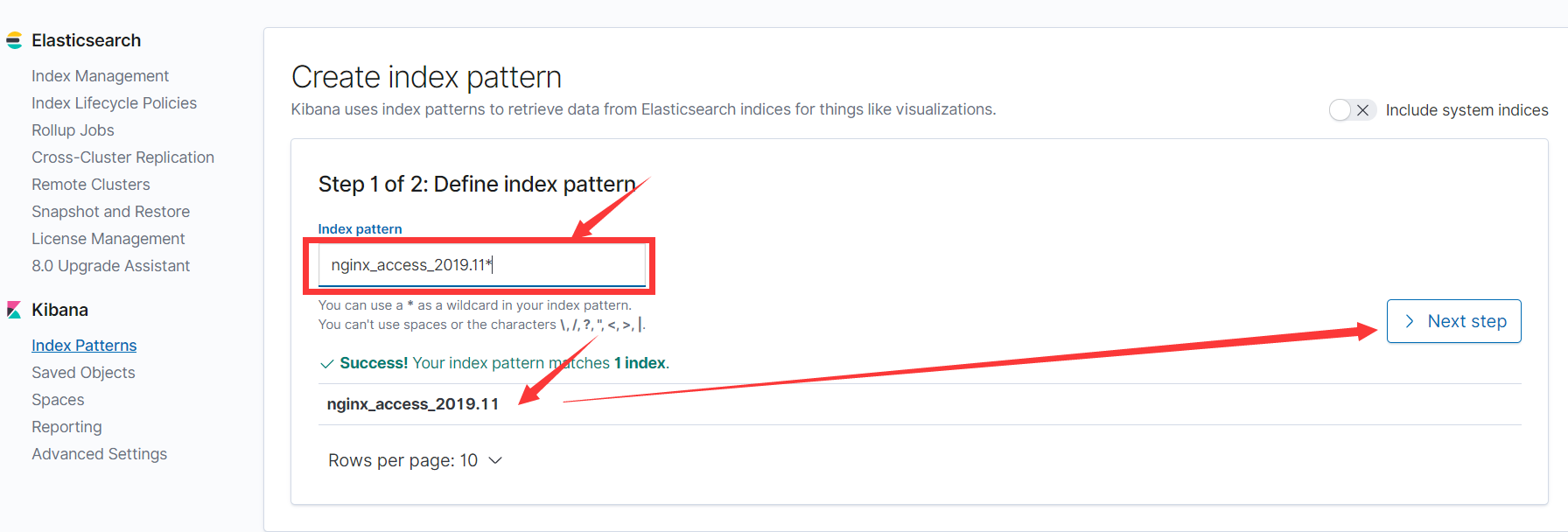
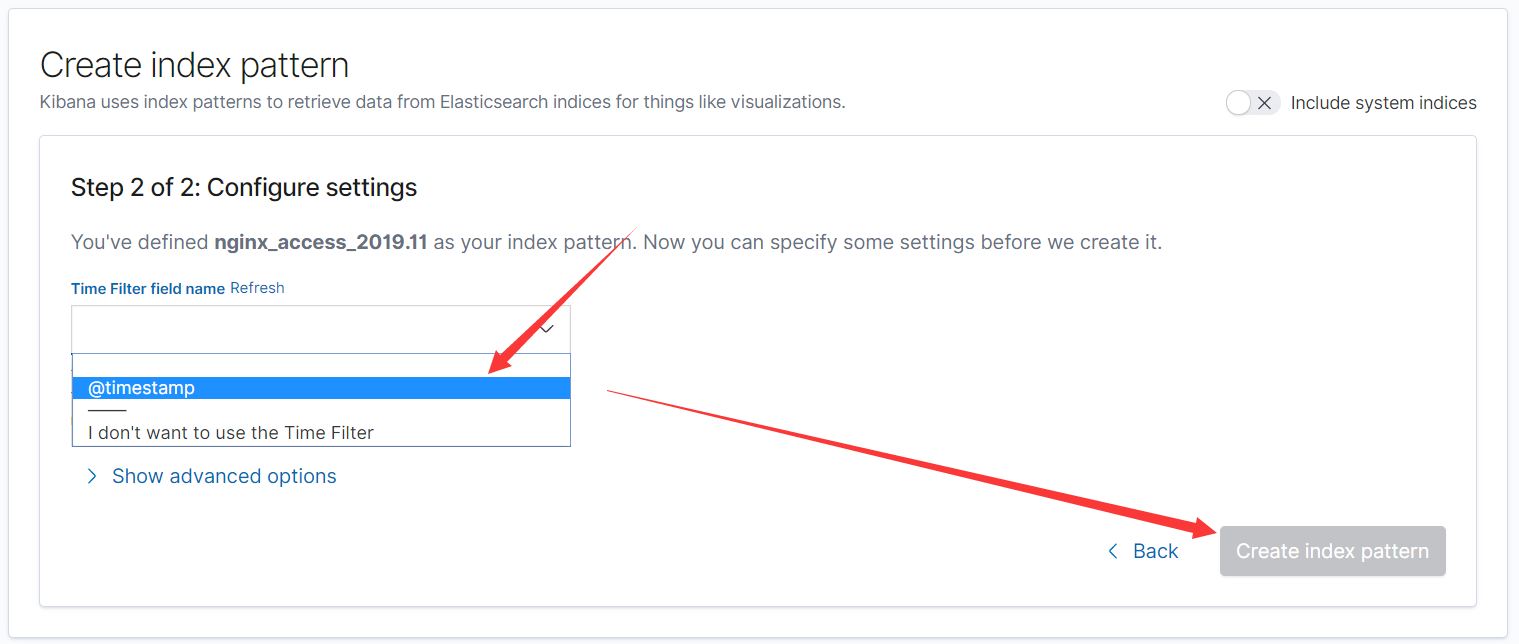
(3)查看之前curl的数据
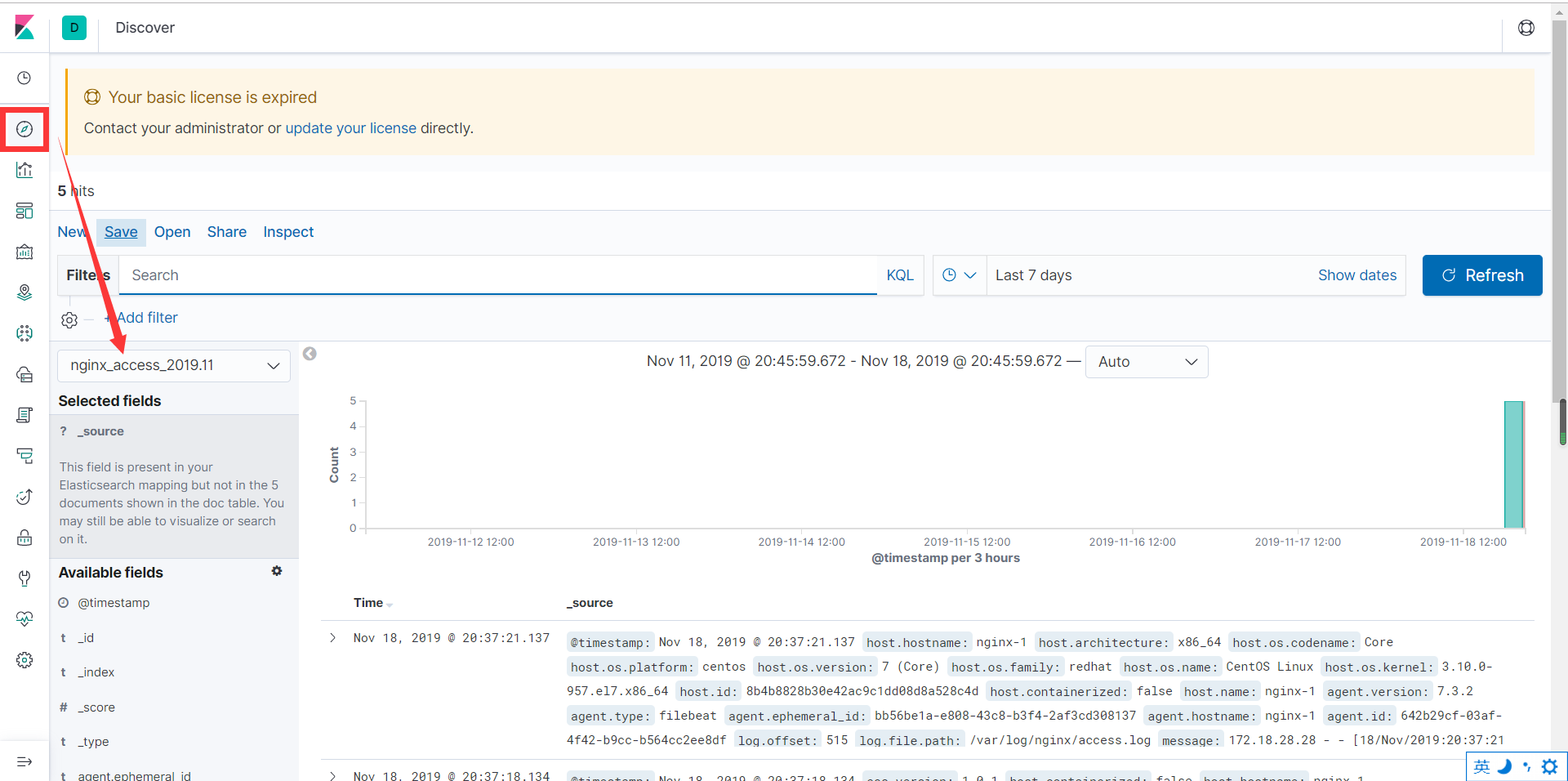

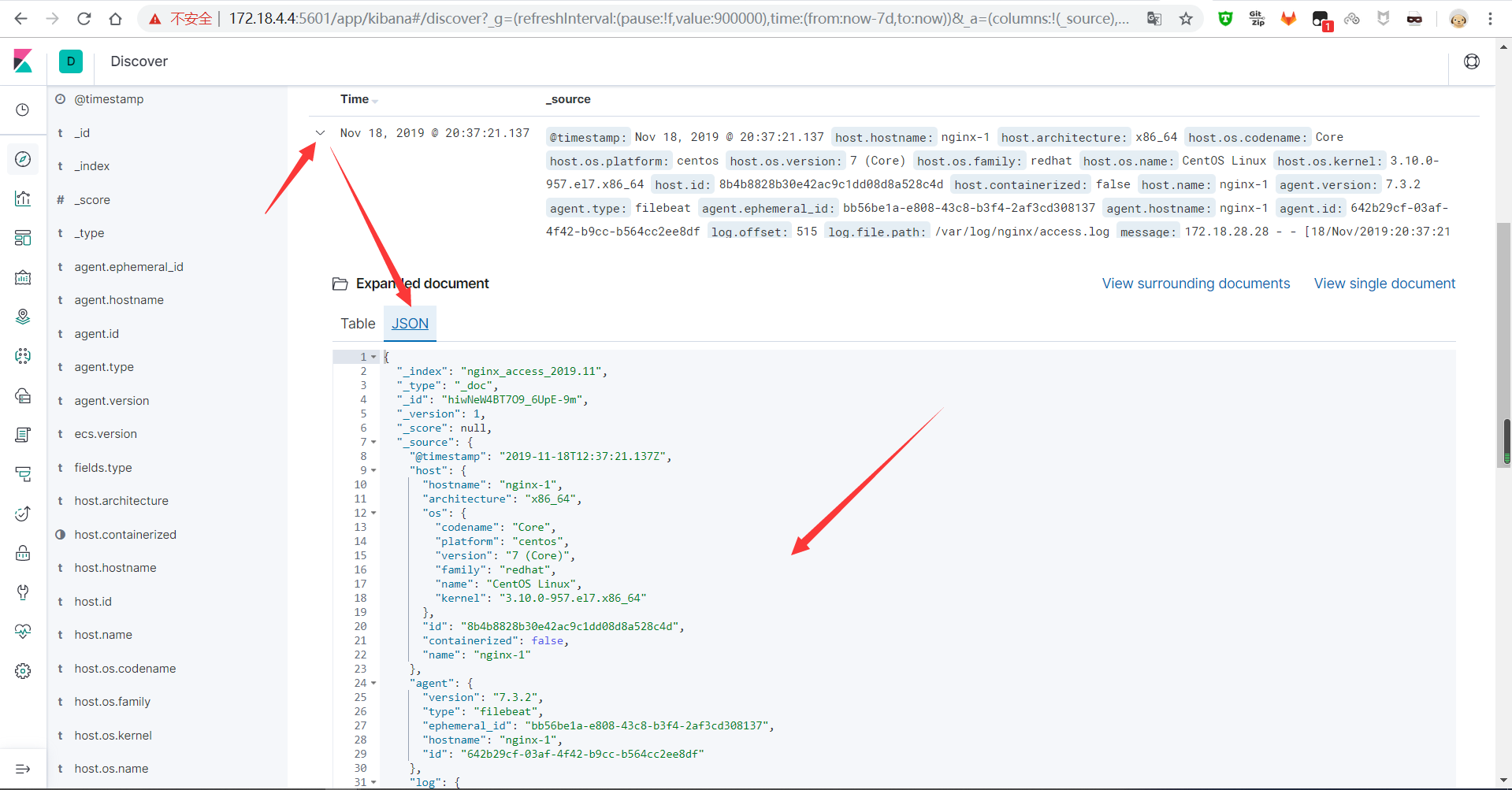
还可以转换成json查看
十一、获取集群的一些信息
1、查看集群的健康状态
[root@node1 ~]# curl http://172.18.3.138:9200/_cat/health?v
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1573846170 19:29:30 007-project green 3 3 10 5 0 0 0 0 - 100.0%


关于这些参数参考:https://blog.csdn.net/weixin_44723434/article/details/90452083
前两个是时间戳,不过多介绍。其余如下:
cluster ,集群名称
status,集群状态 green代表健康;yellow代表分配了所有主分片,但至少缺少一个副本,此时集群数据仍旧完整;red代表部分主分片不可用,可能已经丢失数据。
node.total,代表在线的节点总数量,上图为有3个机子组成集群
node.data,代表在线的数据节点的数量,上图为有3个节点的存储
shards, active_shards 存活的分片数量
pri,active_primary_shards 存活的主分片数量 正常情况下 shards的数量是pri的两倍。
relo, relocating_shards 迁移中的分片数量,正常情况为 0
init, initializing_shards 初始化中的分片数量 正常情况为 0
unassign, unassigned_shards 未分配的分片 正常情况为 0
pending_tasks,准备中的任务,任务指迁移分片等 正常情况为 0
max_task_wait_time,任务最长等待时间
active_shards_percent,正常分片百分比 正常情况为 100%
停掉一个节点:

2、获取集群节点的列表
可以看到,有三个节点,以及机器的cpu负载情况,此时es-3是master
[root@node1 ~]# curl http://172.18.3.138:9200/_cat/nodes?v
ip heap.percent ram.percent cpu load_1m load_5m load_15m node.role master name
172.18.3.139 24 97 0 0.10 0.10 0.17 dim - es-2
172.18.3.138 18 92 0 0.04 0.04 0.05 dim - es-1
172.18.3.253 11 73 0 0.08 0.03 0.05 dim * es-3
node.role: d # 只拥有data角色
node.role: i # 只拥有ingest角色
node.role: m # 只拥有master角色
node.role: mid # 拥master、ingest、data角色
3、列出所有的索引
[root@node1 ~]# curl http://172.18.3.138:9200/_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open nginx_access_2019.11 72E1PXcaQGeKSCI069MZYg 1 1 5 0 109.7kb 54.8kb
green open .kibana_task_manager E6p_8T5vT0KvFyeRUtZzxQ 1 1 2 0 12.9kb 6.4kb
green open filebeat-7.3.2-2019.11.17-000001 _R_qikMqTNGa0Tc0PZ7Odg 1 1 0 0 566b 283b
green open kibana_sample_data_logs Qr7_g9vGRgydtmQpswGp2A 1 1 14074 0 22.8mb 11.4mb
green open .kibana_1 QEcc56yJSHabLauYqIBm3g 1 1 42 0 203.2kb 101.6kb

4、查询节点状态
http://172.18.3.253:9200/_nodes/stats?pretty
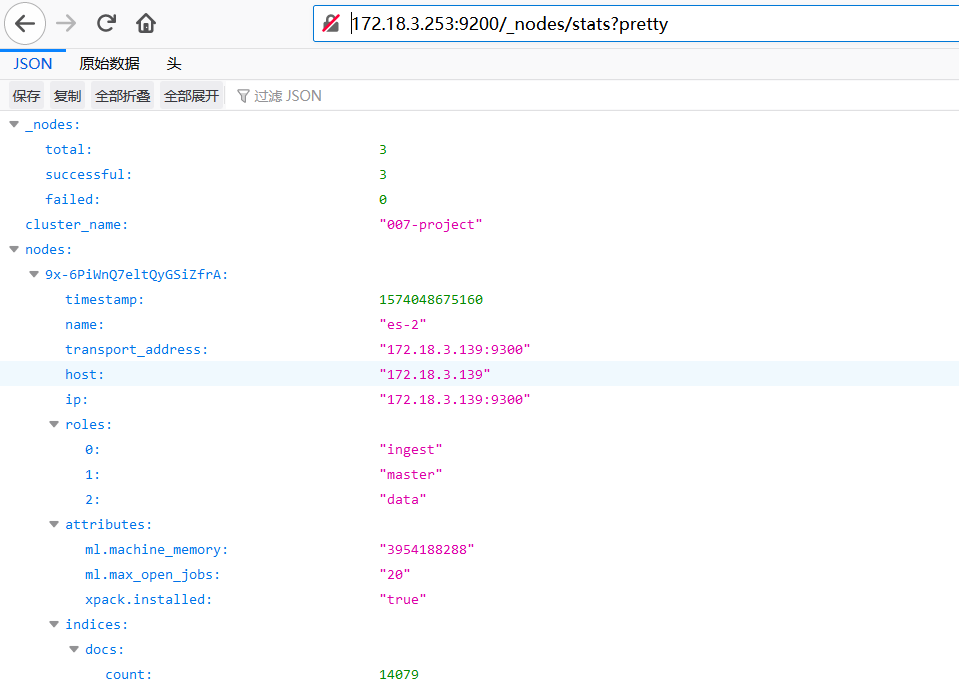
5、查看ES哪些进程在消耗资源
