我们的k8s生产环境也遇到了和这位博主一样的问题,个别节点pod一直创建不起来,dmesg日志和kubelet日志有runc page allocation failure错误,操作系统也是centos7.8的。出现该问题的节点有这个特点:机器上pod运行数量多,pod内存请求值低,l上限值高。相关的文章和issue:
参考:容器创建失败(runc_page allocation failure)排查
参考:Cannot start container: Getting the final child's pid from pipe caused "EOF"
参考:容器启动失败 ERROR: for log Cannot start service log: OCI runtime create failed: container_linux.go:346
该问题可以归为以下问题:
- 节点创建容器失败:

- 容器创建失败(runc_page allocation failure)排查
总结写到前面
出现这种现象的原因是: Linux3.10内核有bug,某些场景下会出现内存碎片过多,无法分配大块内存的情况。
解决此类问题的办法是:
-
建议:升级内核到4.x以上继续观察
-
临时:可以采取重启机器的办法解决,如果机器不能重启,可以采取下面办法缓解:
#清理页面缓存 echo 1 > /proc/sys/vm/drop_caches #即将低阶的page合并成高阶的页框块。 echo 1 > /proc/sys/vm/compact_memory 或者 sysctl -w vm.compact_memory=1
该现象和kmem bug有关联么: 从社区issue来看,或许是有关系的:https://github.com/opencontainers/runc/pull/1921
背景
线上某环境,创建pod时,pod在调度运行的节点一直无法running,describe该pod信息,有如下提示

系统为centos7.7,内核版本3.10.0-1062

排查
- 查看错误节点信息的message日志,发现docker的报错
kuberuntime_manager.go:710] createPodSandbox for pod "media-ai-engine-test-6d75b6f4c6-7jtps_test-media(e1849041-4521-4864-bbbe-d70c70246470)" failed: rpc error: code = Unknown desc = failed to start sandbox container for pod "media-ai-engine-test-6d75b6f4c6-7jtps": Error response from daemon: OCI runtime create failed: container_linux.go:345: starting container process caused "process_linux.go:303: getting the final child's pid from pipe caused \"EOF\"": unknown
从上述报错来看,提示kubelet使用的runtime有问题,环境使用的为docker,从提示getting the final child's pid from pipe caused来看,像是提示docker无法获取到创建的容器子进程信息,于是通过systemctl restart docker重启docker尝试恢复,发现问题依旧。
- 继续排查节点message日志,发现在提示上述pod创建失败日志的上下文,都有如下日志
kernel: runc:[1:CHILD]: page allocation failure: order:6, mode:0xc0d0
Sep 2 12:59:29 VM_16_54_centos kernel: CPU: 0 PID: 8880 Comm: runc:[1:CHILD] Kdump: loaded Tainted: G ------------ T 3.10.0-1062.9.1.el7.x86_64 #1
Sep 2 12:59:29 VM_16_54_centos kernel: Hardware name: Smdbmds KVM, BIOS seabios-1.9.1-qemu-project.org 04/01/2014
Sep 2 12:59:29 VM_16_54_centos kernel: Call Trace:
Sep 2 12:59:29 VM_16_54_centos kernel: [<ffffffffb817ac23>] dump_stack+0x19/0x1b
Sep 2 12:59:29 VM_16_54_centos kernel: [<ffffffffb7bc3d70>] warn_alloc_failed+0x110/0x180
Sep 2 12:59:29 VM_16_54_centos kernel: [<ffffffffb7bc897f>] __alloc_pages_nodemask+0x9df/0xbe0
Sep 2 12:59:29 VM_16_54_centos kernel: [<ffffffffb7c16b28>] alloc_pages_current+0x98/0x110
Sep 2 12:59:29 VM_16_54_centos kernel: [<ffffffffb7be3b28>] kmalloc_order+0x18/0x40
Sep 2 12:59:29 VM_16_54_centos kernel: [<ffffffffb7c22056>] kmalloc_order_trace+0x26/0xa0
Sep 2 12:59:29 VM_16_54_centos kernel: [<ffffffffb7c26611>] __kmalloc+0x211/0x230
Sep 2 12:59:29 VM_16_54_centos kernel: [<ffffffffb7c3ed61>] memcg_alloc_cache_params+0x81/0xb0
Sep 2 12:59:29 VM_16_54_centos kernel: [<ffffffffb7be37d4>] do_kmem_cache_create+0x74/0xf0
Sep 2 12:59:29 VM_16_54_centos kernel: [<ffffffffb7be3952>] kmem_cache_create+0x102/0x1b0
Sep 2 12:59:29 VM_16_54_centos kernel: [<ffffffffc0636dc1>] nf_conntrack_init_net+0xf1/0x260 [nf_conntrack]
Sep 2 12:59:29 VM_16_54_centos kernel: [<ffffffffc06376c4>] nf_conntrack_pernet_init+0x14/0x150 [nf_conntrack]
Sep 2 12:59:29 VM_16_54_centos kernel: [<ffffffffb8044054>] ops_init+0x44/0x150
Sep 2 12:59:29 VM_16_54_centos kernel: [<ffffffffb8044203>] setup_net+0xa3/0x160
Sep 2 12:59:29 VM_16_54_centos kernel: [<ffffffffb80449a5>] copy_net_ns+0xb5/0x180
Sep 2 12:59:29 VM_16_54_centos kernel: [<ffffffffb7acb469>] create_new_namespaces+0xf9/0x180
Sep 2 12:59:29 VM_16_54_centos kernel: [<ffffffffb7acb6aa>] unshare_nsproxy_namespaces+0x5a/0xc0
Sep 2 12:59:29 VM_16_54_centos kernel: [<ffffffffb7a9ae8b>] SyS_unshare+0x1cb/0x340
Sep 2 12:59:29 VM_16_54_centos kernel: [<ffffffffb818dede>] system_call_fastpath+0x25/0x2a
2 12:59:28 VM_16_54_centos kernel: kmem_cache_create(nf_conntrack_ffffa0c378ac2900) failed with error -12
Sep 2 12:59:28 VM_16_54_centos kernel: CPU: 14 PID: 8799 Comm: runc:[1:CHILD] Kdump: loaded Tainted: G ------------ T 3.10.0-1062.9.1.el7.x86_64 #1
Sep 2 12:59:28 VM_16_54_centos kernel: Hardware name: Smdbmds KVM, BIOS seabios-1.9.1-qemu-project.org 04/01/2014
Sep 2 12:59:28 VM_16_54_centos kernel: Call Trace:
Sep 2 12:59:28 VM_16_54_centos kernel: [<ffffffffb817ac23>] dump_stack+0x19/0x1b
Sep 2 12:59:28 VM_16_54_centos kernel: [<ffffffffb7be39d7>] kmem_cache_create+0x187/0x1b0
Sep 2 12:59:28 VM_16_54_centos kernel: [<ffffffffc0636dc1>] nf_conntrack_init_net+0xf1/0x260 [nf_conntrack]
Sep 2 12:59:28 VM_16_54_centos kernel: [<ffffffffc06376c4>] nf_conntrack_pernet_init+0x14/0x150 [nf_conntrack]
Sep 2 12:59:28 VM_16_54_centos kernel: [<ffffffffb8044054>] ops_init+0x44/0x150
Sep 2 12:59:28 VM_16_54_centos kernel: [<ffffffffb8044203>] setup_net+0xa3/0x160
Sep 2 12:59:28 VM_16_54_centos kernel: [<ffffffffb80449a5>] copy_net_ns+0xb5/0x180
Sep 2 12:59:28 VM_16_54_centos kernel: [<ffffffffb7acb469>] create_new_namespaces+0xf9/0x180
Sep 2 12:59:28 VM_16_54_centos kernel: [<ffffffffb7acb6aa>] unshare_nsproxy_namespaces+0x5a/0xc0
Sep 2 12:59:28 VM_16_54_centos kernel: [<ffffffffb7a9ae8b>] SyS_unshare+0x1cb/0x340
Sep 2 12:59:28 VM_16_54_centos kernel: [<ffffffffb818dede>] system_call_fastpath+0x25/0x2a
Sep 2 12:59:28 VM_16_54_centos kernel: Unable to create nf_conn slab cache
关键信息如下:
kernel: runc:[1:CHILD]: page allocation failure: order:6, mode:0xc0d0
........
kmem_cache_create(nf_conntrack_ffffa0c378ac2900) failed with error -12
......
Unable to create nf_conn slab cache
从runc:[1:CHILD]: page allocation failure: order:6来看,提示分配page内存失败。
于是通过free -h检查节点内存信息,发现available内存还很多。
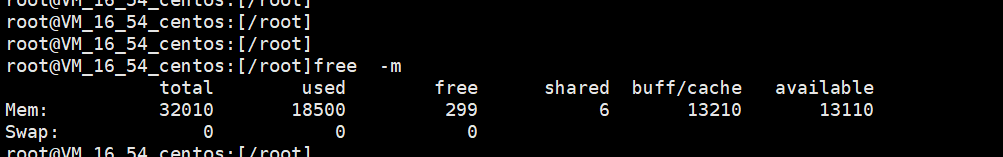
3、从free命令提升内存较多,日志提升page内存分配失败问题,认为和内存碎片有关。 关于linux内存分配的文章,可以参考此篇—万字长文!别再说你不懂 Linux 内存管理了(https://mp.weixin.qq.com/s/mIlwMyB402ZfgFIEOHUQjw)和《Linux内核内存管理算法Buddy和Slab》,https://zhuanlan.zhihu.com/p/36140017,总结而言,linux使用buddy伙伴系统算法和slab方式对内存进行管理。
伙伴分配算法,以4kB为一个页框(page),将所有的空闲页框分组为11个块链表,每个块链表分别包含大小为1(2^0),2,4,8,16,32,64,128,256,512和1024个连续页框的页框块。最大可以申请1024个连续页框,对应4MB大小的连续内存,因为任何正整数都可以由 2^n 的和组成,所以总能找到合适大小的内存块分配出去,减少了外部碎片产生 。
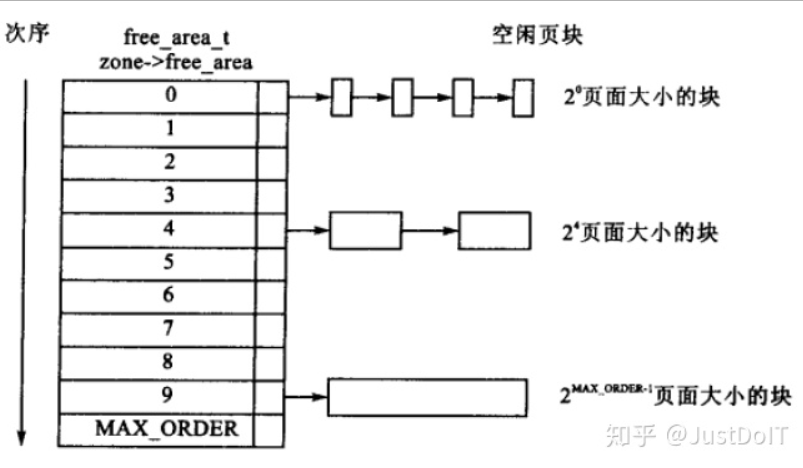
伙伴系统分配出去的内存还是以页框(page)为单位,而对于内核的很多场景都是分配小片内存,远用不到一页内存大小的空间。slab分配器,「通过将内存按使用对象不同再划分成不同大小的空间」,应用于内核对象的缓存。,slab系统核心思想使用对象的概念来管理内存。什么叫对象?这里的对象就是指具体相同的数据结构和大小的某个内存单元。比方上面所说的mm_struct结构体。我们知道,内核每创建一个进程时就需要给其分配mm_struct,这样一来内核中需要维护这个结构体的数目是相当多的,如果全部使用buddy分配器来分配,那么将会产生大量的碎片。而且,这种结构体在内核中分配和释放的频率是很高的,每分配一次又需要对它初始化,用过以后又需要释放,对系统的性能影响也很大。
可以通过slabtop 和 cat /proc/slabinfo查看系统slab信息,如下图为slabtop输出,可以通过name看出对应slab内核对象。
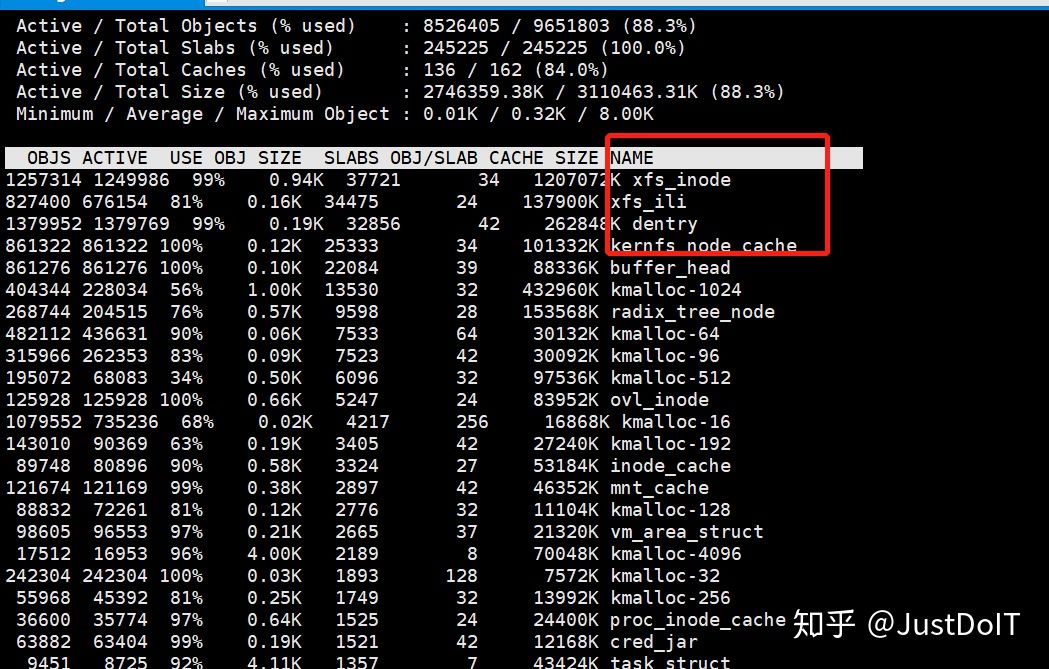
伙伴系统和slab不是二选一的关系,slab 内存分配器是对伙伴分配算法的补充。slab分配器是依赖buddy系统的。诚然,slab系统与buddy系统所要解决的问题是互补的,一个解决外部碎片一个解决内部碎片,但事实上,slab在新建cache时同样需要用到buddy来为之分配页面,而在释放cache时也需要buddy来回收这此页面。也就是说,slab事实上是依赖buddy系统的。
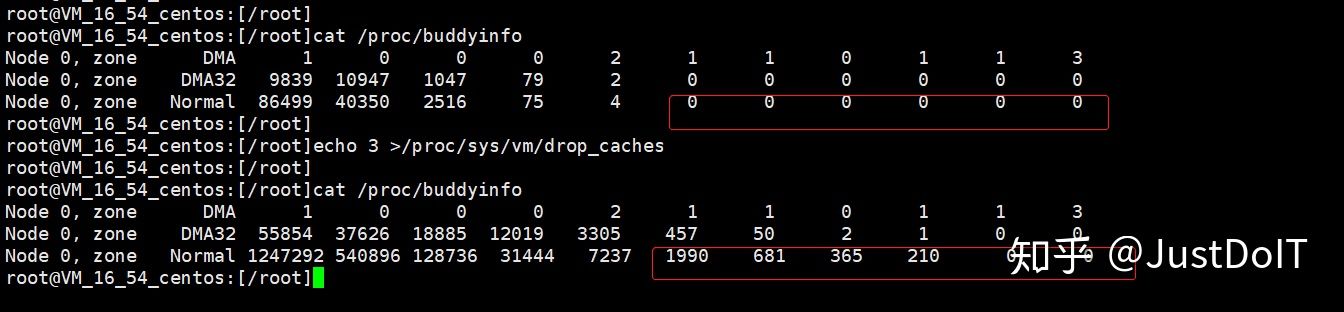
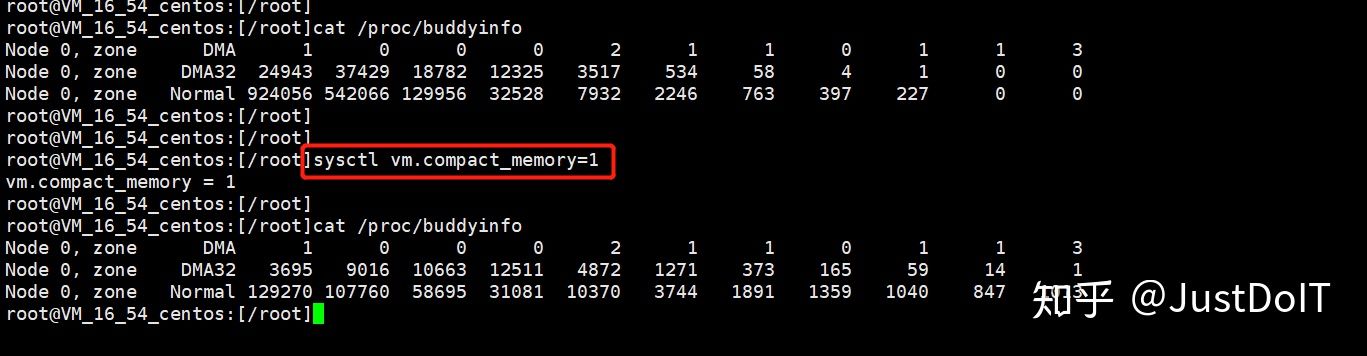
4、系统碎片信息,可以通过cat /proc/buddyinfo 查看,对比发现故障节点2^6的order对应的数目确实为0


解决
其实只能说缓解或者workaround。下面的办法属于缓解症状,还是重启机器好一些,起码短时间内不会再出现。有
1、drop_cache方式
echo 3 > /proc/sys/vm/drop_caches
如下图,通过drop_cache,我们发现buddyinfo中,2^6的order对应的页框block已经不为0
2、主动内存规整方式
即将低阶的page合并成高阶的页框块。
echo 1 > /proc/sys/vm/compact_memory
或者
sysctl -w vm.compact_memory=1
此操作,效果比较明显,可能开销比较大。如下图,内存规整后,2^0的order的page,由924056减小为129270,先前一些数目为0的高阶page,明显增加了很多。
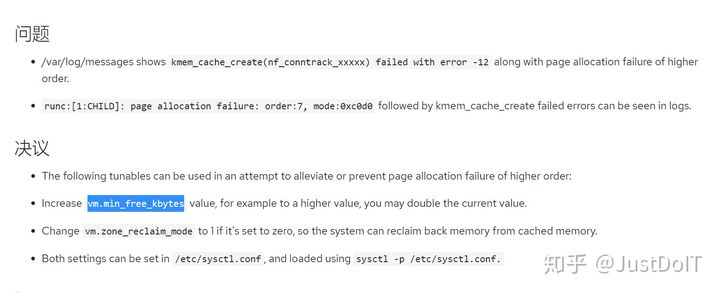
3、参考https://access.redhat.com/solutions/5125461,可以提高vm.min_free_kbytes值进行优化, 可以理解为一种被动内存规整行为。vm.min_free_kbytes用于计算各个zone中影响内存回收的三个参数 watermark[min/low/high],注意vm.min_free_kbytes值不是越高越好,否则可能直接触发OOM。
TO DO
1、为何都已经 page allocation failure了,内核没有自动规整。
调研得知,开启了内核配置 CONFIG_DEBUG_FS和CONFIG_COMPACTION后,内核通过module_init(extfrag_debug_init);在debugfs中创建了如下两个文件:
-
/sys/kernel/debug/extfrag/extfrag_index -
/sys/kernel/debug/extfrag/unusable_index -
内存分配失败原因extfrag_index
针对每一个node的每个zone的每个order,都有一个碎片指数来描述当前的碎片程度,表示的是内存分配失败是由于内存不足还是碎片化引起。 -1000表示内存充足,不需要关心碎片指数。为0代表压根就没free内存了,也不需要关心碎片指数。这两个极端都不需要考虑。越靠近1000,则碎片越严重,很容易分配失败。
-1000 表示分配可以成功
0 就表示分配失败和内存不足关联更大
1000 表示分配失败主要和碎片化有关,数值越接近1000*# extfrag_index的是除以1000以后的值* $ cat /sys/kernel/debug/extfrag/extfrag_index Node 0, zone DMA -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 Node 0, zone DMA32 -1.000 -1.000 -1.000 -1.000 -1.000 0.805 0.903 0.951 0.976 0.988 0.994 Node 0, zone Normal -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 -1.000 0.997 0.999extfrag_index大于500的一般处于order比较大的位置。
和extfrag_index 直接关联的是一个叫 extfrag_threshold 的阈值,默认是500,位置为/proc/sys/vm/extfrag_threshold,这个参数的取值范围是0-1000,在内存不足时候,系统会讲当前的碎片指数(fragmentation index)和extfrag_threshold比较.如果大于extfrag_threshold, kswapd就会触发memory compaction . 所以, 这个值设置接近1000, 说明系统在内存碎片的处理倾向于把旧的页换出, 以符合申请的需要; 而设置接近0, 表示系统在内存碎片的处理倾向于做memory compaction. -
内存碎片化指数unusable_index
unusable_index表示某个内存区域中各个order的内存碎片情况:
在我的系统上输出如下:*# cat /sys/kernel/debug/extfrag/unusable_index* Node 0, zone DMA 0.000 0.000 0.000 0.002 0.004 0.010 0.010 0.031 0.073 0.157 0.326 Node 0, zone DMA32 0.000 0.036 0.124 0.275 0.490 0.703 0.822 0.849 0.854 1.000 1.000 Node 0, zone Normal 0.000 0.036 0.119 0.264 0.478 0.725 0.910 0.984 0.997 0.999 1.000 Node 1, zone Normal 0.000 0.025 0.088 0.202 0.382 0.620 0.845 0.964 0.991 0.997 0.998
解释一下该值的含义:
- 该值表示一个
zone中所有的空闲内存中,有多少是不能满足分配order大小的内存 - 该值的范围最小为
0,最大为1 0代表没有内存碎片,表示所有的空闲内存都能满足内存分配1代表内存碎片严重,表示所有的空闲内存都不能满足内存分配
例如:Node1 的Normal 区中,order为10的unusable_index的值为0.998,表示99.8%的空闲内存都不能满足2^10大小的内存分配请求。
但是日志显示 page allocation failure: order:6时为何没有自动规则内存,是没有达到watermark水位线启动kswapd内核线程,还是没有超过 extfrag_threshold 的阈值?
2、什么造成了内存碎片