说明:这不是一篇pandas入门教程,也不是什么经验之谈。因为我也没有认真去学习pandas的入门知识,然后实现自己想要的一些功能写的自己日常的一些简单的笔记罢了
为什么会接触pandas
最近刚好需要处理一个csv文件,设计到数据筛选这一块,还有需要用python来发送html网页。Linux上我可以很熟练的使用sed,awk完成数据筛选的操作,但是python这一块因为不是用得很熟练,写起来比较笨,然后我在github上找了下,发现了个写的还可以的代码:https://github1s.com/laidefa/Python_SentEmailExcel/blob/HEAD/README.md
然后我看到了这位大佬使用pandas模块来将表格的数据来导出成html网页,加了一些css代码后,竟然还很漂亮,于是我就查了以下,发现pandas主要是做数据分析的,生成html只是一个小功能,太棒了,于是乎,就花了两个下午研究了下。
pandas如何快速学习
pandas官网文档: 官网文档不会有错的
Pandas教程(菜鸟教程) :百度搜索Pandas,第一个是官网,第二个便是菜鸟教程,偶尔相信下百度,还是不错的
pandas小知识点
1、安装pandas模块
python -m pip install pandas
2、导入pandas模块
import pandas as pd
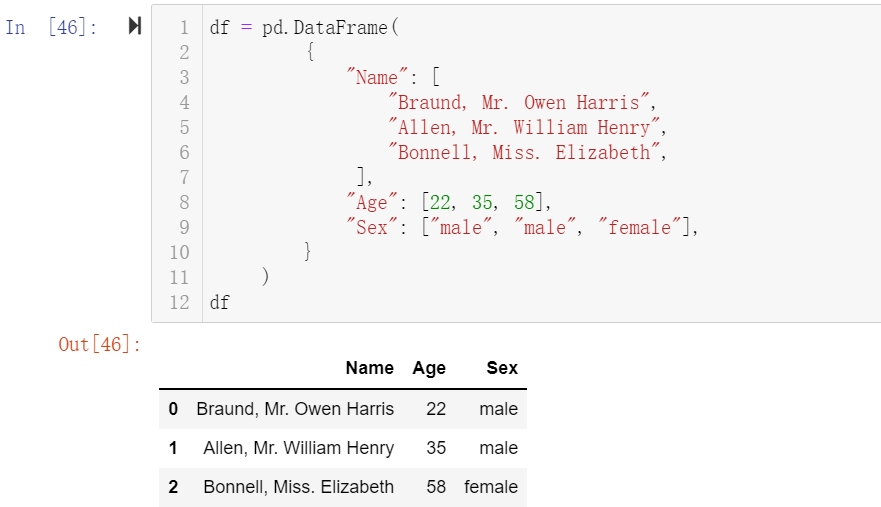
3、将一个字典类型数据转换为表格
df = pd.DataFrame(
{
"Name": [
"Braund, Mr. Owen Harris",
"Allen, Mr. William Henry",
"Bonnell, Miss. Elizabeth",
],
"Age": [22, 35, 58],
"Sex": ["male", "male", "female"],
}
)
df
然后jupyter会输出一个漂亮的表格
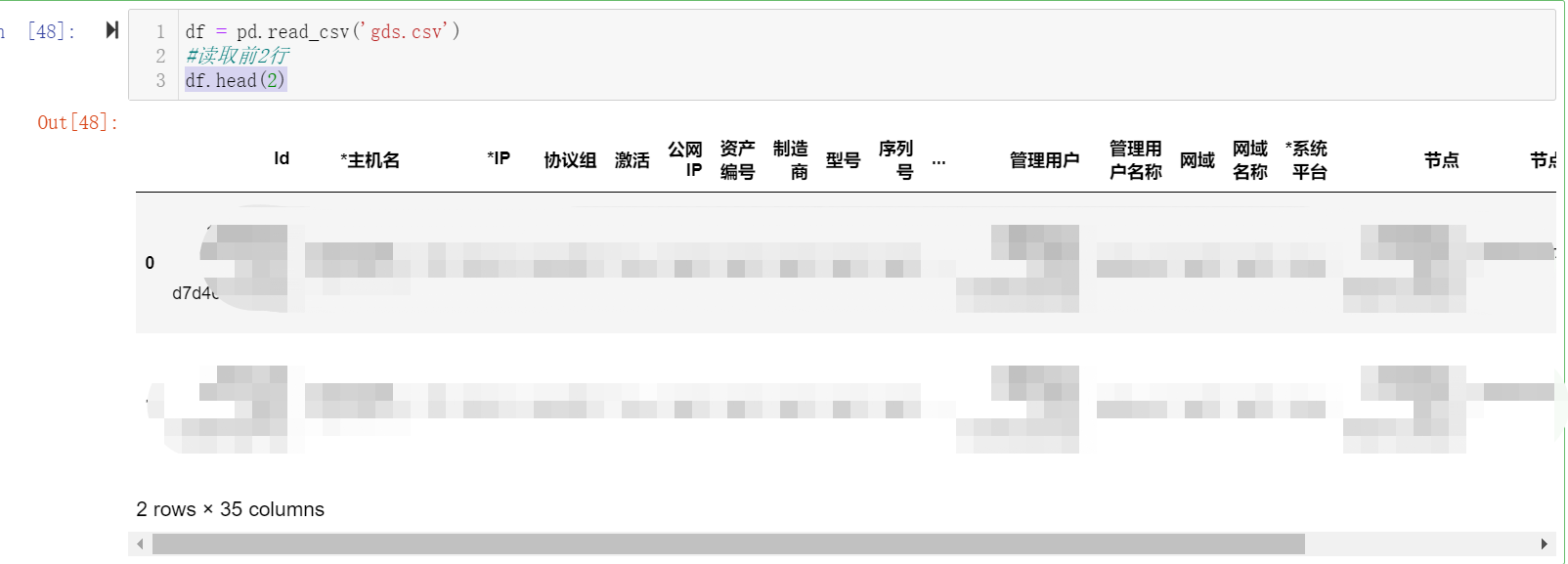
4、读取csv文件
df = pd.read_csv('gds.csv')
读取前两行
df.head(2)
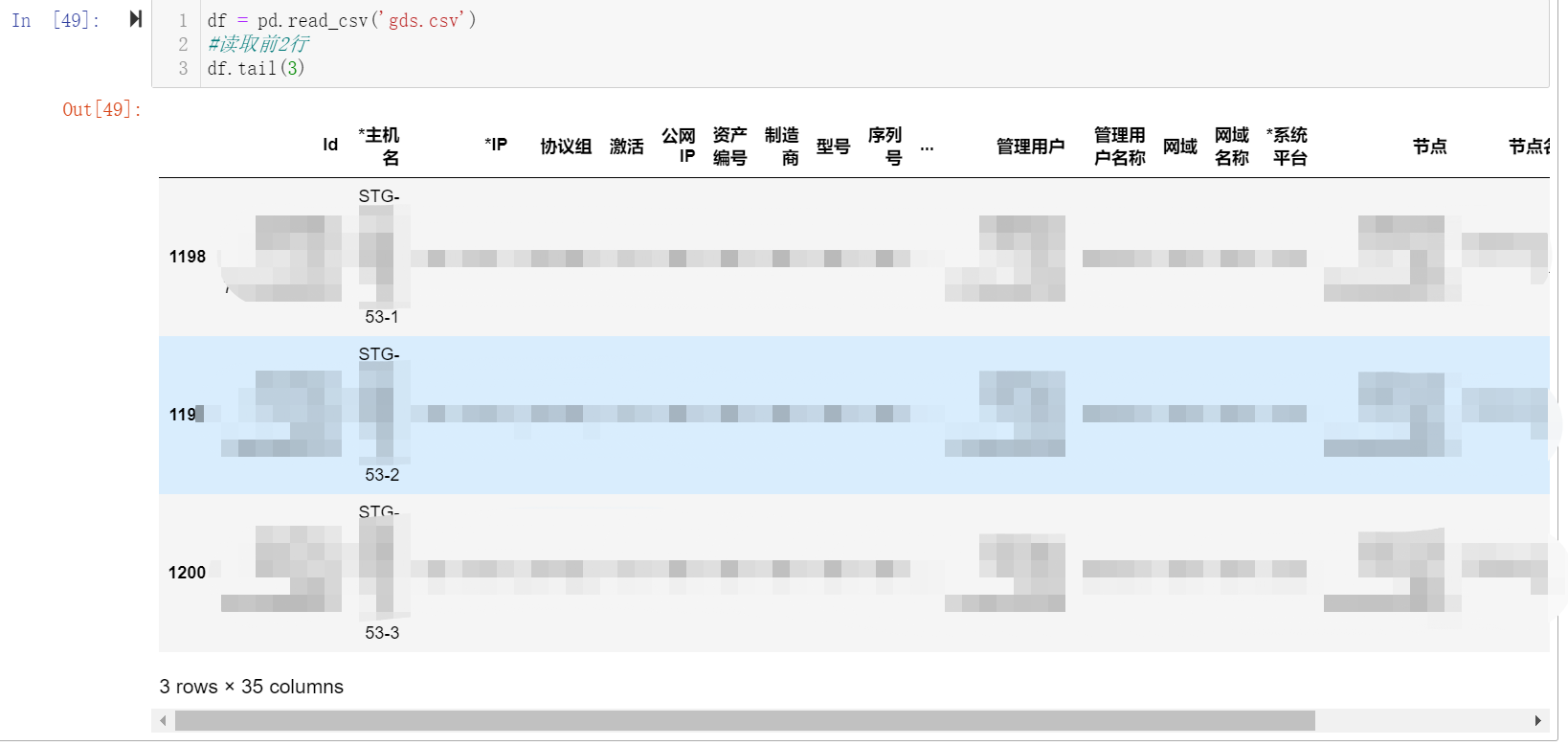
读取后三行
df.tail(3)
返回表格的基本信息
df.info()
#输出了有多少行,多少列,每列数据类型等等
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1201 entries, 0 to 1200
Data columns (total 35 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Id 1201 non-null object
1 *主机名 1201 non-null object
2 *IP 1201 non-null object
3 协议组 1201 non-null object
4 激活 1201 non-null bool
5、数据清洗
参考:https://www.runoob.com/pandas/pandas-cleaning.html
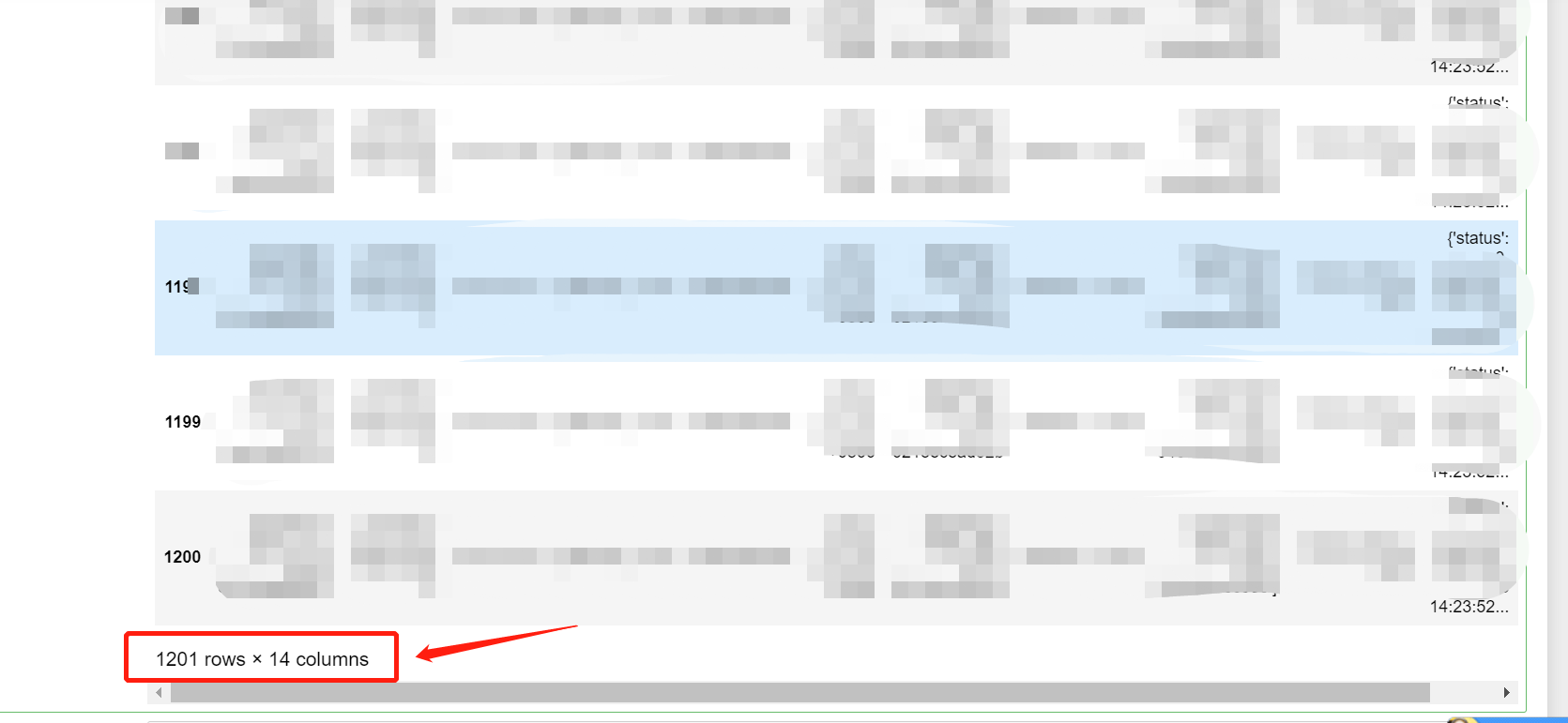
去除空列,没去掉空列有35列,去掉后只剩下14列
#数据清洗:设置参数 axis=1 表示逢空值去掉整列
df.dropna(axis=1, how='any', thresh=None, subset=None, inplace=False)
6、保存到csv文件
# df.to_csv()
# 例如将上面清洗后的数据保存到test.csv文件里面
df.dropna(axis=1, how='any', thresh=None, subset=None, inplace=False)
df.to_csv('test.csv')
7、loc函数筛选数据
参考:https://www.jianshu.com/p/805f20ac6e06
loc函数筛选主机名包含master或harbor的行,
df.loc[df['*主机名'].str.contains('master|harbor')]
筛选主机名包含master或harbor的行,并且筛选指定的几列
df[['*主机名', '*IP', '管理用户名称', '*系统平台', '节点名称']][df['*主机名'].str.contains('master|cargo')]
8、将csv表格转为html网页
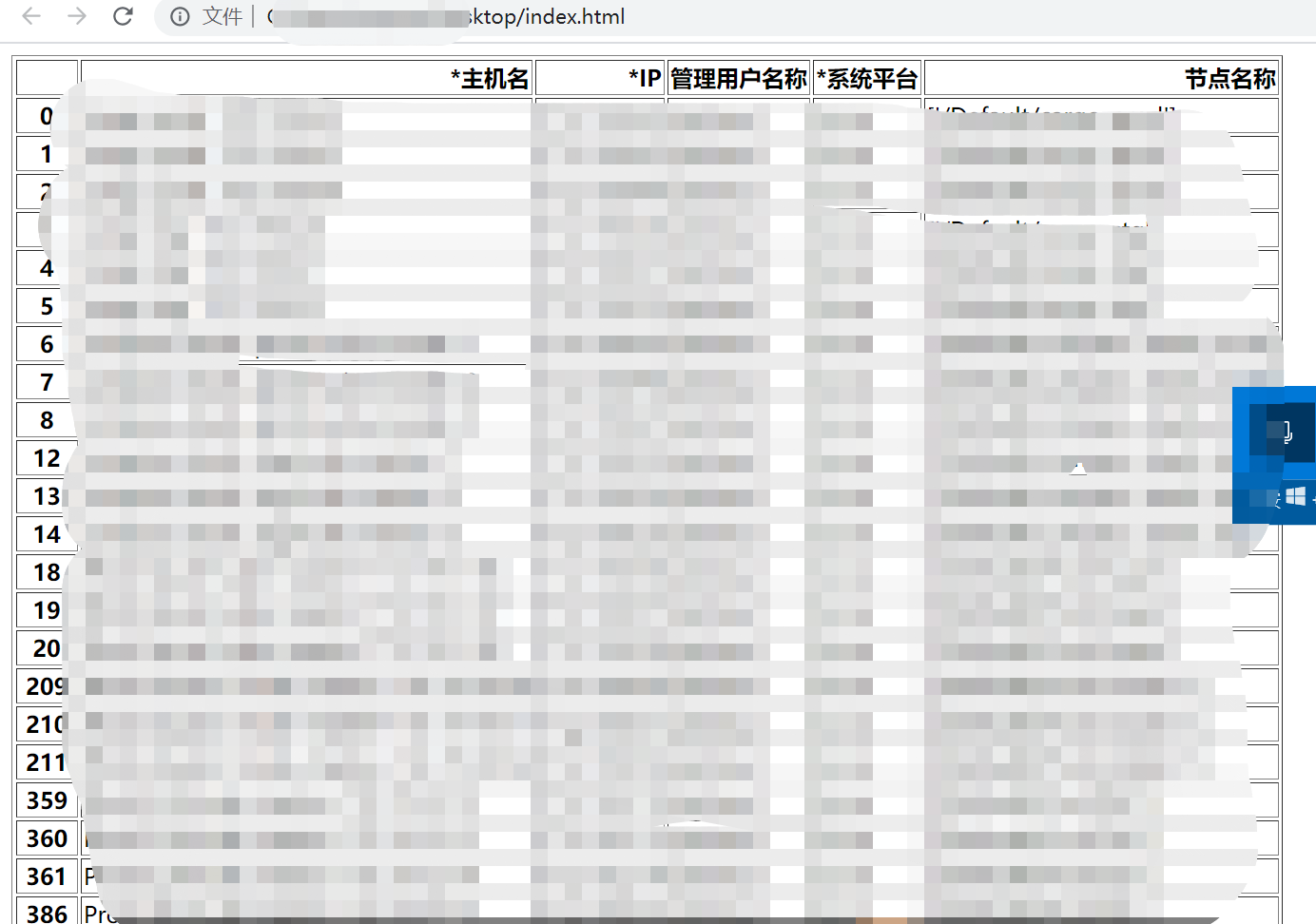
df_html = df.to_html(index=True)
生成的页面是这样的,不是很好看
可以加上下面几行css代码,给表格换个边框
<style type="text/css">
table {
border-right: 1px solid #99CCFF;
border-bottom: 1px solid #99CCFF;
}
table td {
border-left: 1px solid #99CCFF;
border-top: 1px solid #99CCFF;
}
table th {
border-left: 1px solid #99CCFF;
border-top: 1px solid #99CCFF;
}
</style>
再使用下面代码居中文字,修改表头,修改首行颜色等等,效果立马不一样
html=str(df_html).replace('<table border="1" class="dataframe">','<table border="0" class="dataframe" style="width:100%" cellspacing="2" cellpadding="2">')
html=str(html).replace('<tr style="text-align: right;">',' <div style="text-align:center;width:100%;padding: 8px; line-height: 1.42857; vertical-align: top; border-top-width: 1px; border-top-color: rgb(221, 221, 221); background-color: #3399CC;color:#fff"><strong><font size="4">我是大标题</font></strong></div><tr style="background-color:#FFCC99;text-align:center;">')
html=str(html).replace('<tr>','<tr style="text-align:center">')
html=str(html).replace('<th></th>','<th>num</th>')

我的目的基本达成了,有空了再学pandas